The D-Team has worked over the past couple of years to integrate processes for digitized and legacy born-digital content into Project Electron infrastructure. In addition to updating policies and workflows, we have developed a microservice to package bags; an application to store, calculate, and assign PREMIS rights statements; and a microservice to create image derivatives and IIIF Manifests.
These systems substantially change in how we’re getting digitized content onto DIMES. When I wrote Automating Archivematica Ingests 3 years ago, we had come a long way in our use of Archivematica and other systems. As a result of the work that I just mentioned, we’ve come even further, with additional automation and streamlining of our workflows. I’m happy to provide an update on what we’re doing now.
To briefly recap our previous workflow for getting digitized content through Archivematica and available in DIMES:
- Scripts would be manually run in order to: a. Create a PREMIS rights csv file b. Create an ArchivesSpace csv file c. Package digitized content d. Move packaged content to the Archivematica transfer source
- Transfers would be started by a script (cron job or kicked off manually)
- Archivematica would create a digital object in ArchivesSpace (using information in the ArchivesSpace csv file) for the DIP
- A nightly cron job would move PDFs from new DIPs to our web server and create a variety of thumbnail derivatives.
- After a nightly data refresh and index, our front-end system would use the URL in the digital object record’s file version field to link to the access files on our web server
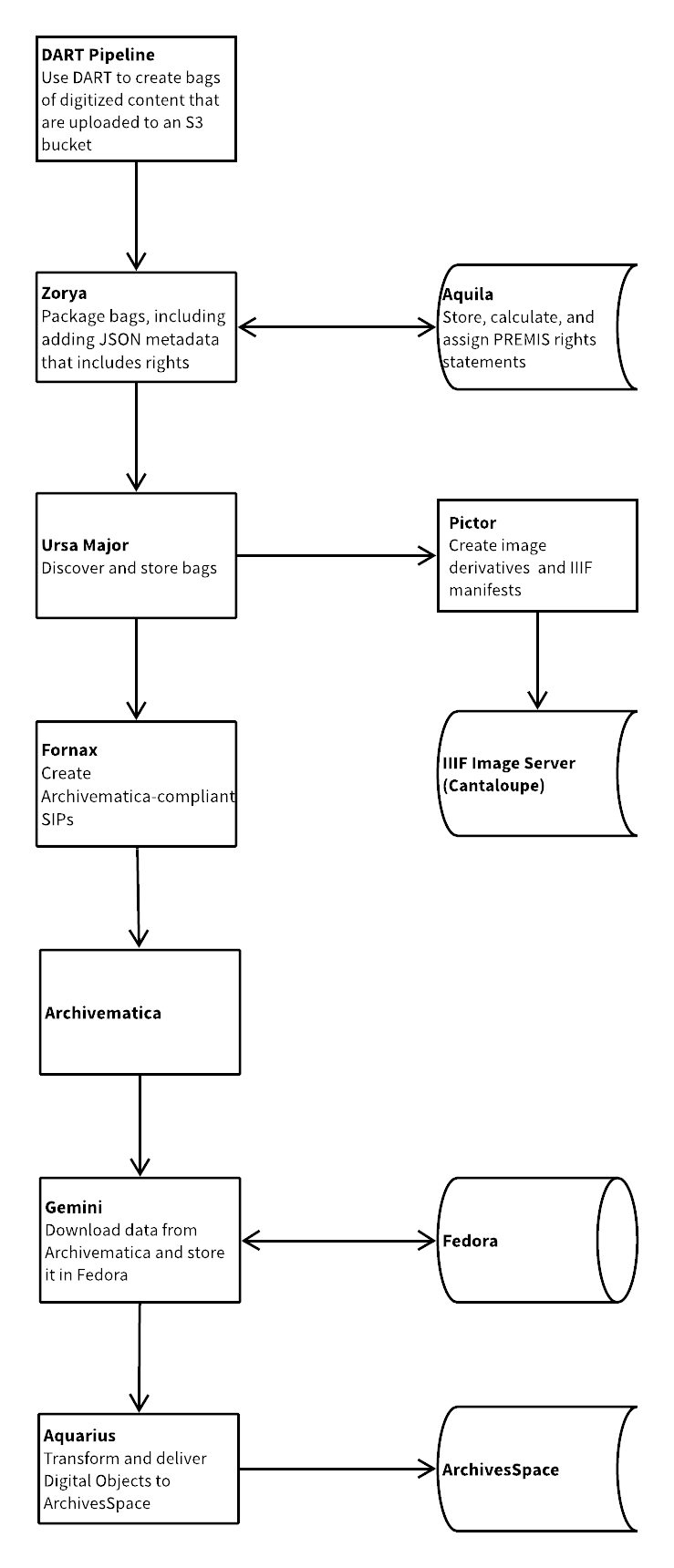
And this is what our new workflow looks like:
- The DART digitization pipeline is run on a user’s workstation. This is a Python script that uses AP Trust’s DART to create bags and upload them to an S3 bucket. The name of each bag is the ArchivesSpace refID for that component.
- The first microservice in this pipeline, Zorya, checks the S3 bucket and downloads the bags. It then processes the bags, which includes getting rights information from Aquila, and sends the packaged bags to Ursa Major.
- Aquila, our system to create and store PREMIS rights statements, has an API to assemble rights information. This API expects rights statement IDs and date information, and it returns rights data JSON that conforms with our local schema.
- Ursa Major is the first microservice in this pipeline that existed beforehand. It sends the package from Zorya to Pictor as well as to Fornax.
- Pictor is our IIIF derivative and manifest generation microservice. It uploads these derivatives and manifests to our S3 bucket.
- Fornax is our microservice that creates an Archivematica-compliant SIP. It restructures the package it receives from Ursa Major and creates a PREMIS rights CSV. It also validates the CSV using Archivematica’s validation endpoint. It then bags and repackages the restructured package and starts an Archivematica transfer.
- In our digitization workflow, we use Archivematica to only create an AIP, not a DIP.
- Our microservice Gemini uses Archivematica’s post store callback API as a trigger to download the AIP and store it in Fedora. It then sends information about the AIP to Aquarius.
- Aquarius creates a digital object in ArchivesSpace and links it to the appropriate archival object.
- In DIMES, our finding aid portal, if a digital object exists for an archival object, the IIIF page is linked to and a PDF download is provided.
While our new processes involve more applications, only the very first step is kicked off by a user. This new process allows us to fully automate our pipeline from getting digitized content, to preserving it, to making it accessible online. By separating functionality into discrete microservices, each application can do one thing really well–and it’s easy to isolate and troubleshoot when something goes wrong. The headaches around dependency management and networking issues are drastically reduced by using these applications instead of running scripts from local workstations. And by integrating systems this way, we’re able to update data much faster and have control over what data is written to our systems like ArchivesSpace.