In preparation for our new discovery system, processing archivists at the RAC have been working on cleaning up some of our data in ArchivesSpace in order to facilitate improved searching. A large chunk of data that has been problematic for some time is our collection of agent records in ArchivesSpace. We simply had too many agents, none of which are standardized, and most which were duplicates of agents that were already in our system, misspelled, or contained incorrect data. Some of our finding aids had too many agents at the file-level, and other findings aids didn’t have any linked agents at all. The state of our agent records makes it difficult for researchers to use the “Filter by Creator” feature, since there is no consistency as to how many agents are assigned, or the level in which they are assigned to a finding aid. In this post, we’ll discuss how we evaluated and cleaned up the agents in our repository.
Of course, the varied and complex issues surrounding our agents prompted us to continuously reinvestigate the problems we were attempting to resolve and alter our strategy. Our initial plan to address the many, many agents in our repository was to write a script to remove the links to all agents that have no “source”. Through thinking about this more, and looking at our agent data, we realized that just because an agent doesn’t have a proper source, like LCNAF or local, doesn’t mean it’s not a valid agent. There were plenty of agent records that were missing a source and proved to be linked appropriately to data in ArchivesSpace. We realized we needed to take a much more in-depth look at our agent data.
Mo Agents, Mo Problems
With assistance from the Digital Strategies Team, we were able to get a .csv file export of all agent data in our ArchivesSpace repository. Having all of our agent data in a spreadsheet gave us the ability to use filters in Excel to sort the data alphabetically, or by its source ID (LCNAF, local, or none). This allowed us to take notice of the sheer amount of agents as well as some of the problematic names and acronyms.

Looking at our data, we found even more complicated issues surrounding our agents. A lot of these examples really made our heads spin! Here are a few examples:
Duplicate names: There were at least three different John D. Rockefeller agents, all linked to different material and there was no way to decide which one was the “real” John D. Rockefeller agent since the agent records for JDR were exactly the same.
Misspelled names: Our repository contained spelling variations of last names like “berg” and “burg, or “stein” and “stien”. In some cases, these agents were the same person, despite having different spellings.
Inverted names: In some cases, agents with inverted names like “Alexander Heard” and “Heard Alexander” were actually the same person.
Different middle initials: Sometimes people with the same first and last name, but different middle initial, were actually the same person. For example, Roy E. Harrington, Roy S. Harrington, and Roy L. Harrington was actually, interestingly, the same person. We discovered they were the same person by looking at the files/collections they were linked to.
Shoehorned LOC subject headings: We found that Library of Congress subject headings were shoehorned in to fit a specific foundation officer. For example, this LOC agent “David Henshaw, 1791-1852” was connected to a 1980 foundation report written by a different David Henshaw. The original agent was added to this report because they shared the same name, but it’s obviously incorrect since the original agent was not alive at the time the report was written.
You might be wondering how these convoluted agents even made it into our repository in the first place. More often than not, these agents came from a bad OCR reading that was never addressed prior to importing that data into ArchivesSpace.
You may also be wondering why so many of our recently added records were attached to bad agents, why couldn’t we just “pick the correct agent” so that we do not make the problem worse. Well, this goes back to our initial problem - we simply had too many agents. There were so many agents, variations, and duplicates that searching for agents became extremely difficult (even for an archivist). How can one choose between three “Ford Foundation” agents that are exactly the same?
Enhanced Agent Merging in ArchivesSpace
We needed to find a way to decide which agent was the right agent and remove the rest. The amount of research needed to choose one agent record over another was going to make using a script impossible. As far as I am aware, scripts need to be able to recognize patterns and in this case, there were no standard patterns. Some agents didn’t have sources and were correct, and other agents had sources but were the wrong person! It was chaos, and sometimes this level of chaos requires human intervention.
We ultimately decided to use the Enhanced Agent Merging function that was included in a recent ArchivesSpace update. This functionality allowed us to select an agent and merge duplicate agents into it. Prior to merging, you can select “Compare Agents” which brings you to a new screen that shows the two agent records side-by-side, allowing you to choose which information within the agent record is merged.
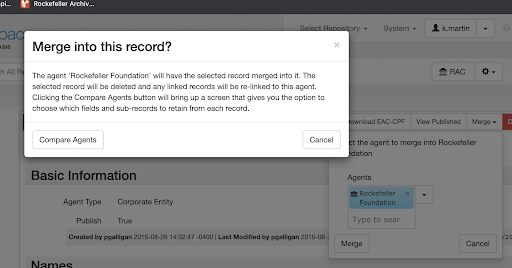
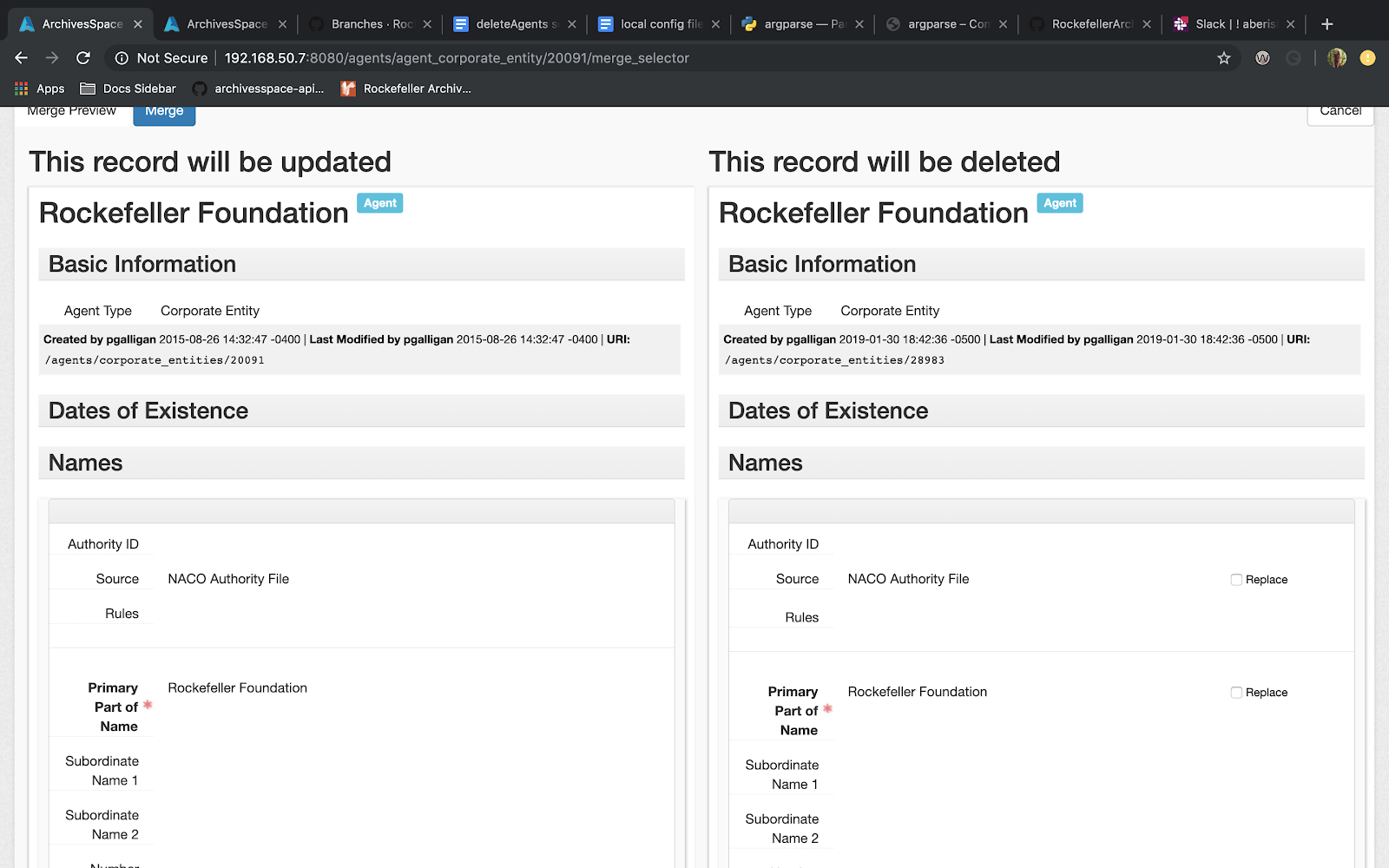
Although merging agents was manual work, it utilized a functionality that already existed in ArchivesSpace, thereby avoiding the work it would take to create a script that would be able to handle the level of logic required to decide which agent to merge. Using the Merge Agents functionality also retains all existing links and eliminates the need to delete the duplicate agent record.
To move forward using this tool, we utilized the ArchivesSpace agent export spreadsheet to divide and conquer this work. With the help of Processing teammates, Katie Martin and Darren Young, we split up the spreadsheet into three sections and added a column called “Keep, Merge, Delete” that allowed us to keep track of the actions that were taken for each agent.
Remove Agents Python Script
After addressing the duplicate and incorrect agents in our repository, we still had to deal with the remaining file-level agents that existed in a few of our finding aids, like the Ford Foundation grants and catalogued reports. With guidance from Head of Processing, Bob Battaly, and the Digital Strategies team, we decided to remove all file-leve agents in the Ford Foundation grants and catalogued reports. Most of these agents were not particularly useful. In most cases, the agent is named in the file title and the grant/report could be found easily by searching the name of the person in DIMES. Additionally, assigning file-level agents is not currently part of the RAC’s processing workflow, so these finding aids would look much different than the rest of our repository.
To complete the final stage of the project, we decided a script would be the most effective way to remove thousands of agents at once. The choice to automate this process was simple when compared to the complications we faced in the initial merging process. The inspiration to utilize a script came from simultaneous work to create a script that removes unnecessary access notes en mass from finding aids. With help from the Digital Strategies team, we soon had a working script that was able to unlink all agents from file-level archival objects within an indicated collection guide. Our aim was to unlink the agents from the file, not to delete these agents from ArchivesSpace completely. Many agents were still useful points of entry to other guides in the system, and our previous work removed the particularly problematic agents (i.e. duplicates and misspelled names).
To run the script, a user provides the corresponding resource ID in the command line. The script then iterates through files and unlinks all agents. Originally, before we knew exactly what we were dealing with, the script focused on unlinking agents with ‘ingested’ and ‘local’ sources. Once we realized we wanted to delete ALL agents from the Ford Foundation Catalogued Reports and Ford Foundation Grant guides, the script was modified slightly to reflect this change. This functionality is preserved on the script’s GitHub page, and could be useful going forward. We ran the script at night to avoid disruptive ArchivesSpace slowdowns. We also notified IT and Digital Strategies team members when we would be running the script. Ultimately, it took a month running the script once per day to unlink all the file-level agents.
Final Numbers and Reflection
From the beginning, the project required extensive collaboration. We needed to plan how to tackle the problem together, evenly divide the work, create standardized guidelines for merging and deleting, keep IT and digital team members informed throughout the process, and record our joint progress effectively. In addition to the teamwork aspect, as we learned more about the agents in our system, the project needed to be reevaluated frequently. Although the goal remained the same: remove all unnecessary agents from our system by merging or deleting, the path we took to get there was sometimes meandering or unknown. This project was a lesson in jumping in and letting go of what we thought we knew about our data. We needed to fully start the project and manually evaluate the data before we could know it was possible to automate a large chunk of the project. We had to weigh the costs of manual and automated work, but in the end, it took a bit of both.
The agents cleanup project took around three months for three processing archivists to complete. Overall, we manually merged or deleted 6,704 agents from ArchivesSpace which was 18% of all agents in our system. By running the script, we unlinked 82,041 agents from 18 Ford Foundation finding aids. Hopefully these efforts, along with new agent guidelines, will be helpful for researchers and staff as we move forward to a new access system.