You might remember that earlier this year I wrote a post about Metadata Cleanup and Ford Foundation Grants that gave a very basic overview of how I went about reconciling thousands of subject terms against the Library of Congress. This reconciliation was essential in helping us gain control over data that we did not create, but that we also identified as possibly extremely valuable to researchers. This post will give an in-depth and updated account of how I hobbled together a (mostly) automatic way to check large amounts of topical terms against the Library of Congress. It still requires some hands-on work and quality checking is a must, but it cut a hundreds of hours job down exponentially.
We started the project with a spreadsheet of data pertaining to 54,644 grant files created by the Ford Foundation and containing some extremely valuable research information (grant date, grant amount, purpose of the grant, creator, topical subjects, and geographic area). Only about 8,390 of these individual grant files had pre-assigned subject terms, but most of them had multiple subjects, and many of these subjects were compound constructions of two or more terms. To make matters a little more complicated, the original creators stored all subjects for a grant record in a single cell. However, the creators consistently used semicolons to separate individual subject terms.
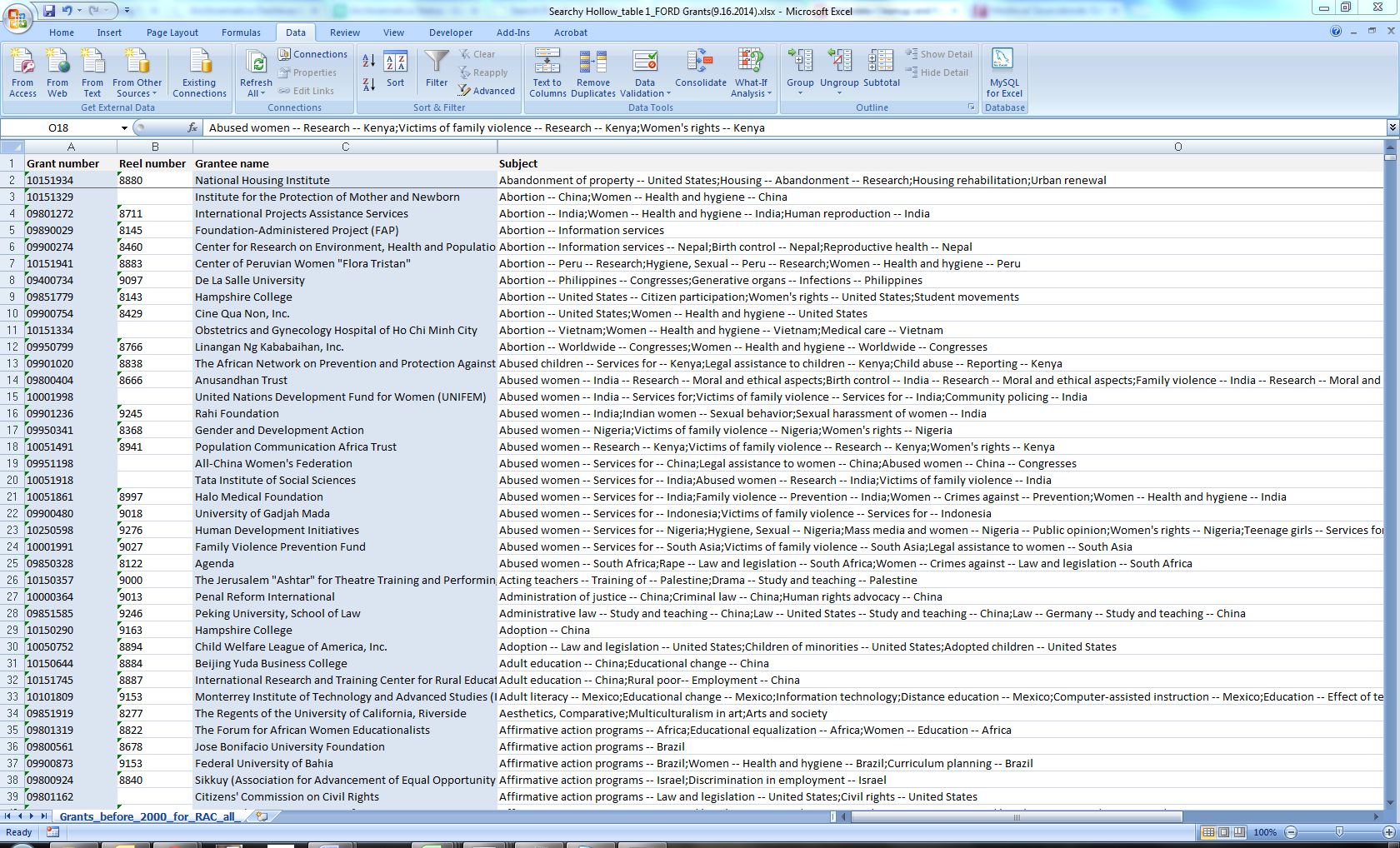
My first step was to use Excel’s text to columns tool to separate subject terms into different columns whenever it found a semicolon. This effectively isolated each individual subject into its own cell. I then consolidated all of these into a single column. This resulted in somewhere around 80,000 topical subject terms. Next, I wanted to get a list of only unique subjects, so I took this column of subjects and created a pivot table out of the data. Using a pivot table I was able to create a list of each subject without any duplicates. If you were working with only simple subject terms, you would be ready to start reconciling these against LCSH, but I was dealing with compound subject terms, and those needed some work.
Due to some prior testing, I knew my preferred reconciliation service could not handle compound subjects well, so I needed to find a way to work around these subjects. Luckily, the Ford Foundation constructed compound subjects the same way as the Library of Congress; two dashes separate each subject term. I made use of Excel’s text to column functionality again, this time separating the data into individual columns wherever a “-“ appeared. Unlike the previous step, I kept these columns separate because I eventually wanted to put the terms back together with the dashes. I was going to have reconcile each of these columns separately given the structure of the Excel spreadsheet, but that was a price I was willing to pay for the overall automation of the project. As the final step to cleaning my data, I used Excel’s trim function to remove any unwanted spaces from the beginning and end of a cell. The end result was about 10,000 rows of unique subject terms that I was now ready to reconcile.
After researching similar projects on the web, I discovered that using Open Refine would allow me to work with the LCSH reconciliation tool provided by Free Your Metadata. After importing the spreadsheet into Refine, I used the system’s built in ability to cluster and edit data to correct any casing, spacing, and spelling using the nearest neighbor, which created a more standardized dataset and removed any variations in the controlled vocabulary. You can see a full list of data cleaning suggestions here.
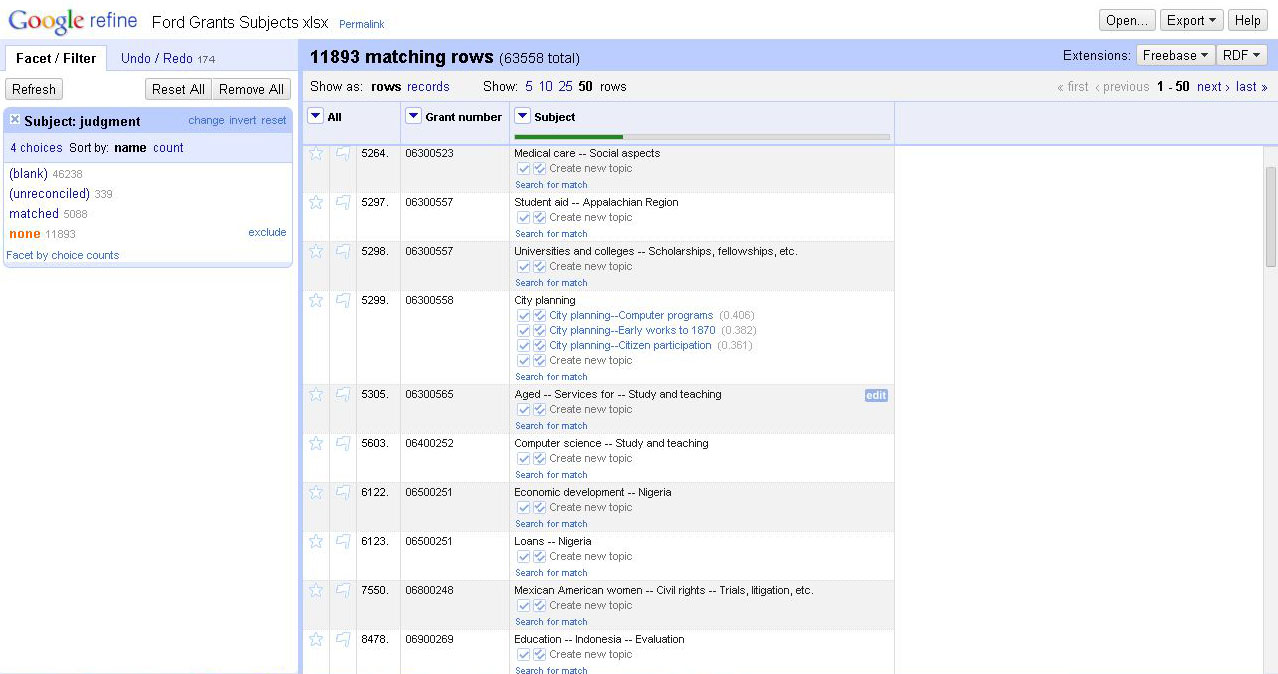
The next step was installing an RDF extension that interacts with Refine and lets the user set up a new reconciliation service against different backend options. Given my needs, and its availability through a SPARQL (a query language that can retrieve data stored in an RDF framework) endpoint, I set up the reconciliation service against the backend described here. After running the reconciliation, Refine will provide a list of facets with matching category assignments or unreconciled terms. The initial reconciliation provided a surprisingly high amount of automatic exact matches (about 40%). Unfortunately, that was as far as the automatic matching could take me; I would have to approve or find matches for the remaining 60% myself using the suggestions provided in Refine. The reconciliation tool will provide suggested best candidates for matches that it did not feel comfortable matching on its own, and, in most cases, these candidates are 99% matches to the term. Small errors like extra spacing, misspellings, or capitalizations can stop the automatic reconciliation, but you can have Refine replace all terms with a suggested term with a single click.
Manually reconciling the suggested matches with high suggestion ratings took me to about 90% complete and matched subject terms. The remaining 10% of the terms required some searching in the LC Linked Data Service, but once I found a term that fit our purpose, I could have Refine quickly replace all of the original terms with the updated version.
I then repeated the process for each column of subject terms. When finished with reconciling, I exported the Refine data to an Excel spreadsheet, re-combined any split compound subjects with dashes, and then copied and pasted the new column of terms right next to the old column of terms, making sure that the new and old matched up correctly.
You might recall that I only reconciled unique terms, which meant that I needed some way to quickly find every instance of an old term, and replace it with its reconciled version. While I do not have much experience with Visual Basic, I managed to cobble together a script to find the value from one column in a range of values, and then replace it with the value in a second column.
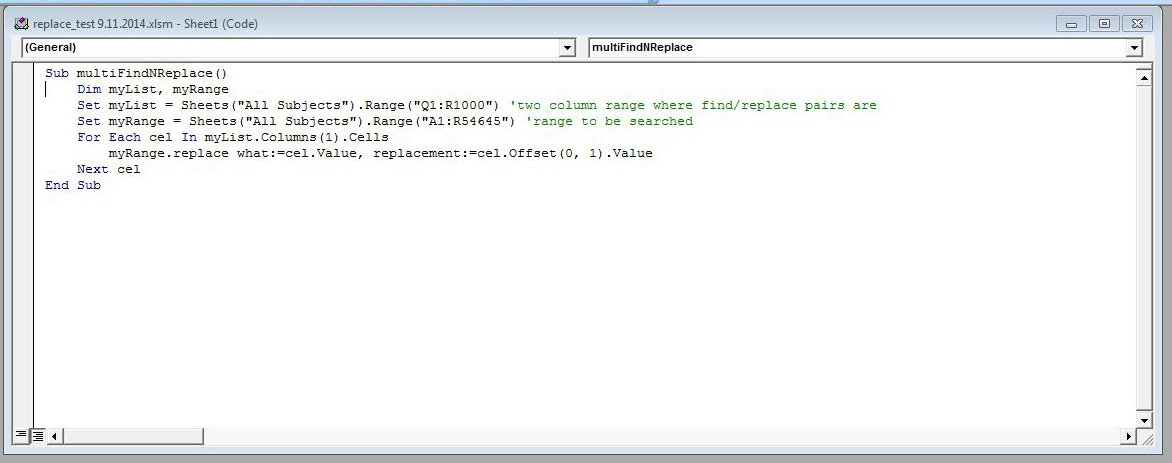
Ultimately, I wasn’t able to completely automate the process, but by cobbling together a few different systems, I was managed to cut down the time it would have taken to complete the task. I’m sure there’s room for improvement, but the hands-on manual work also gave me an opportunity to check the quality of the reconciliation, and helped me better understand the data.