About a year and a half ago, we decided that we were going to make the switch from our current Archival Management System, the no-longer-updated Archivists Toolkit, to its next iteration, ArchivesSpace. The RAC officially began preparing ourselves for ArchivesSpace in January of 2014.
At the beginning of the project, we were working with AS version 1.0.4, which was the fourth iteration of the system since its official release at the end of September 2013. Throughout the process, the ArchivesSpace project team primarily consisted of four members: myself, Digital Team Assistant Director Sibyl Schaefer, our Systems Administrator Jose Morillo, and Lead Digital Archivist Hillel Arnold. The project team was small, our goal was to adopt a user-centric approach to the migration, so we worked closely with members of the Archival Services, Processing, Reference, and Collections Development groups, and involved them in almost every step of the process.
I started working at the RAC in late September 2013, fresh out of graduate school, having touched the system less than five times in my life up to that point. While the RAC did not hire me specifically for the ArchivesSpace transition, within my first month of work, Sibyl placed me in charge of the migration. I spent much of the next year going from feeling like a babe in the woods to an expert, and hopefully this series of posts will give context to how I became an expert at the system. I’ll outline the major steps we took along the way with the amount of hours I spent on each stage, so you can have a comprehensive understanding of how long it might take someone with slightly above average computer skills to make the same journey. I should note that much of the work happened concurrently, but in interests of clarity and legibility I have broken the work into discrete segments. The entire project took about 550 FTE hours over 11 months.
Now that I’ve set the stage, let’s jump into an actual review of the work!
INSTALLATION AND SETUP – 40 hours in 11 months
The very first thing I did was install ArchivesSpace on my work desktop and get a local instance of it up and running. Local installation took less than thirty minutes to get up and running, and literally included unzipping a group of folders to a folder on my desktop. I spent about five hours familiarizing myself with the system, and going back and forth between AT and AS to compare and contrast the terminology, user interface, and base functionality. After one day, I felt confident that when we put the system up on a server, I would be able to identify whether it was running properly or not.
I enlisted the help of our System Administrator in getting our virtual machine and server set up. We set up an internal-facing server running on CentOS and Apache. If you’re already familiar with Linux, you might be able to do this without the help of a Sys Admin. In our case, the Sys Admin completely set up the Virtual Machine, bought the domain names we would be using for the live environment, and set it so that only users on the internal RAC network would be able to access the domain.
After the VM was up and running, getting ArchivesSpace installed was as easy as following the instructions in the ReadMe file! I had root access to the distribution, so, with the help of my handy Linux Pocket Guide, I got the system running against MySQL in less than two hours. All it took was setting up a blank MySQL database, using wget to download the latest ArchivesSpace release, unzip the source code, running one setup script included with the source code, and editing ArchivesSpace’s configuration file to match the name of our database; all of which is outlined in detail in the installation instructions.
The whole process of setting up the server and making sure that everything was working took about 10 hours in that first month. In the next eleven months, server maintenance, upgrading through seven versions of the system, and setting up a second development server took a total of 30 hours, and was one of the easiest parts of the entire process. There were a few hiccups along the way (installing LDAP took a little finagling by our Sys Admin), but once you can install the program, it’s really simple to get it up and running again in under an hour as long as you have a Virtual Machine already set up. I filled those remaining thirty hours with installing and uninstalling ArchivesSpace upwards of 50 times, exploring the directory structure and source code, and testing restores from backup for both the entire VM and the backend database. With the system up and running, it was time to look back at what the RAC had done in the past, and asses the current state of the data in its Archivist Toolkit installation.
Cleaning and Preparing AT Data for Migration – 25 hours in 3 months
Before I delve into the Rockefeller Archive Center’s metadata, I want to give some quick stats about our AT installation at the time of migration. We had 13,944 name records, 8,246 subject records, 3,264 accession records, 11,304 resource records, and 2,401 digital object records.
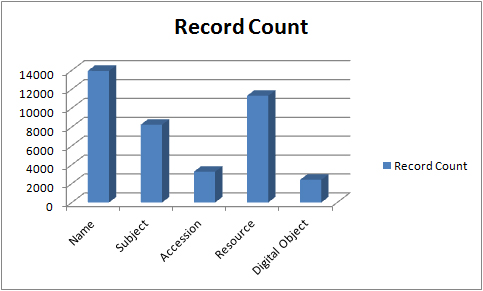
I give these numbers to illustrate that we had a fair amount of data in our system, and much of it had not been checked or standardized since we first moved to AT. However, we had migrated from Re:Discovery to AT a few years earlier, and that required much more cleaning and standardization of data. As such, while our metadata might be dirty in some places, the majority of our AT data took little work.
{kind=link}
My first step was to check our controlled value lists in AT and look at our different data options for every single field. It became immediately clear that some of our lookup list data was extremely messy thanks to archivists adding data without first cross-referencing spellings or variations that might already exist in the database. What follows is a completely unedited list of every single extent type we had in AT pre-cleanup:
- bound volume
- Box
- box(es)
- Cubic feet
- cubic ft.
- document box
- document boxes
- document cases
- feet
- film reel
- Folder
- Folders
- Hanging folders
- item(s)
- Linear feet
- microfilm reels
- pages
- record cartons
- reels
- tapes
- Volume
- volumes
The issues with this list should be clear, and this was not even the worst list of offenders; container and instance types had even greater variation. For those dealing with the same sort of issues, there are some really easy steps you can take to tackle this problem. AT allows admin users to edit, merge, and delete Lookup Lists from within the system, and you can take huge steps to alleviating your data problems by massaging these features.
I merged any values that were obvious duplications (volume/volumes or box/boxes) across all Lookup Lists. I deleted all list items with a record count of zero because we were obviously not using the terms and they were cluttering our data. After merging and deleting useless terms, I took the slightly cleaned list of terms, and sent them to the groups that handled Accessioning and Processing for their thoughts. I asked for their opinions because these archivists work with the system the most and best know what type of data they need. Making these changes and decisions took about 15 hours at most, and most of that time I spent sitting down with group leaders, walking them through why we wanted to make these changes, and then refining the lists we came up with. The actual changes to the Lookup Lists only took a few clicks of a button in AT.
Here’s a quick list of many of the Lookup Lists that we made changes to: Subject Term Types, Subject Source, Acquisition Types, Extent Types, Instance Types, Container Types, and Finding Aid Status.
Unfortunately, not all of our data issues were as easy to resolve as the Lookup Lists. One of the largest data issues I ran into was that we had duplicate subject names, some with valid subject types like Topical or Geographic, and duplicates with the same subject name, but with a “local” subject type. It quickly became clear that this happened due to importing EAD finding aids without proper subject type attributions. As time went on, archivists used both the local and Topical terms to describe collections, effectively making it impossible to just delete one of the duplicates. ArchivesSpace will try to change any unrecognized subject type to a Topical term upon migration, but when that Topical term already exists, the system will not migrate the specific local term and any record linking to it will lose that link, and thus that descriptive information.
Fixing these issues with duplicated data took a little more expertise, and some more cooperation with our Sys Admin. I had some experience working with MySQL, and I knew that I could leverage my SQL skills to track down the duplicate data faster and easier than looking line by line in AT. I asked our Sys Admin to make me a copy of our AT database’s SQL dump, then imported it into a local schema using the MySQL workbench. From here, I just used a quick SQL select command (select subjectTerm from subjects;) to get a quick list of every subject in our database. From here I could export the results into a CSV file. Once I had the CSV file, I made a pivot table of all the subject terms, and included a count of how often each term appeared. Any subject term with a value above one in the count column would require merging. I still had to manually complete all of the merges, which took a couple of hours, but was much shorter than searching through AT for any duplicates. The entire process of finding and fixing duplicate subjects took about ten hours to complete.
After making the above, we were ready for our first full test migration from a local AT instance to our server running ArchivesSpace. I don’t want to mislead anyone in saying that these issues were the only things we had to change about our data, but they were the only ones we made before doing a migration of our entire database.
In the next installment, I will discuss in detail the steps I took to check and further clean our data following each test migration, leading all the way up to our final data check pre-live launch along with our process for reporting and troubleshooting migration errors! The next post will discuss some of the early migration issues, the importance of the ArchivesSpace user group, and the absolute necessity of creating test records for easy data migration checks. Stay tuned!