Migration Testing, Data Quality Checks, and Troubleshooting Errors – 295 hours in 8 months
After finishing the initial data cleanup, it was time to start testing our migration; the only way to identify major issues was to do a dry run. To set up for our initial testing, I took a MySQL dump of our AT database, loaded it up into an empty AT instance, and then installed the AT Migration Plugin. To install the AT Migration Plugin, just place the scriptAT.zip in your base AT plugins folder, either on a server or on your local machine.
Our first migration test did not go smoothly.
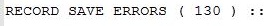
When I first saw that number, I admit I was worried, but upon further inspection I realized that most of these save errors stemmed from duplicate subject terms. AT will occasionally let you create two subjects with the same title from ArchDescriptionSubjects table in the database and SubjectTermT if you import the data directly into the system, which the RAC had done in the past with large groups of materials. The below image shows an example of one of our duplicate subject terms that we needed to merge before migration. This failed because the AT to AS migratory had already migrated data from ArchDescriptionSubjects to the AS Subject table that shared the same title and SubjectTermType.

ArchivesSpace is not able to migrate these duplicate subject terms, and then will throw back an error whenever it tries to migrate a linked resource or accession record.
You might remember from the last post that I searched for duplicate terms prior to migration, but I missed about 15 duplicate terms through human error. These were easy to identify and correct in AT. However, I noticed that a significant number of Accession records had not carried over.

And the ArchivesSpace migration log was less than helpful.
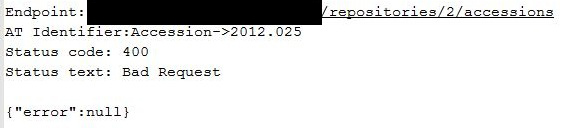
It was at this point that the ArchivesSpace user forum listserv became invaluable. I had no idea what these errors were trying to tell me, so I asked the migration tool developer directly. He told us that it was most likely a problem with the migration tool, and that he would have to update it. While the migration reporting was generally good about telling us what went wrong, I never would have been able to figure the above error out by myself, and our only recourse was contacting the developer and waiting for a response.
Besides the migration tool errors, we also ran into a problem with resource records being too large to migrate.
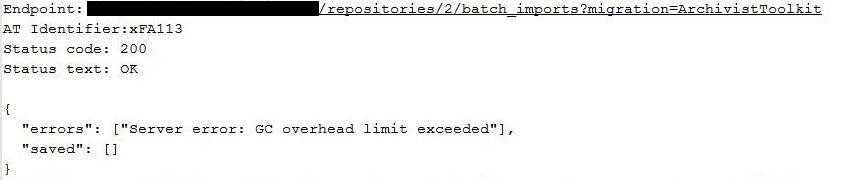
Even when turning up our java heap settings to 1 GB, we had two resource records that were just too large to migrate using the migration tools. The migration would slow to a crawl when it hit these, and after about two hours, would just skip over them due to their size. We eventually had to split these resource records into four smaller segments, which worked, but we were never able to migrate the single resource over without issue.
We also had issues with duplicate EAD IDs, end dates coming before start dates, and duplicate digital object METS identifiers, which were all caused by previous data imports into AT and EAD imports.

I easily fixed all of these issue by going into our AT instance and manually changing the offending records. It would probably be possible to update some of these settings directly in the backend database, but given the relatively low number of issues, I went for a more manual approach. However, the above are only the issues that the migration tools identified; checking migrated content once it made it into the system was imperative to a successful transition.
Data Quality and System Functionality Checks
Prior to migration, I created test records in AT, with the field’s name as the content in each field, and all linked together.
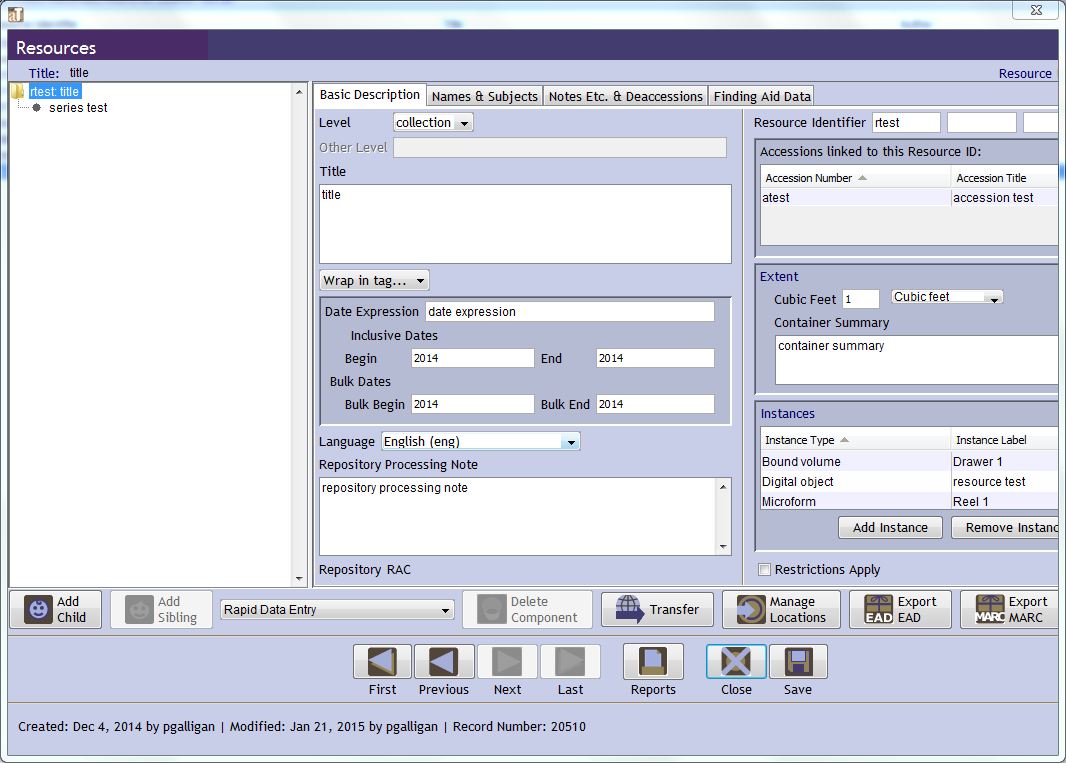
These records included an Accession, Resource, Digital Object, Name, and Subject. We used these test records to definitively see which field mapped to which in ArchivesSpace, and also whether there were any issues with the migrated data. After each migration I would check every field in these test records against the data entered in AT, and note any differences in the content or display. We also checked a few other records from each section because we knew that other issues could arise with full records as opposed to the test records.
Some of the early issues included:
- Access Restrictions notes migrating as Use Restrictions
- Finding Aid Filing Titles not migrating
- Finding Aid Language not migrating
- Digital Object dates defaulting to digitized date not creation date
- Digital Object file version URIs that are not valid URIs break the display of Digital Objects
- Restrictions apply Boolean values not migrating
- All lowercase spellings in controlled value lists
- Controlled value list items not already in ArchivesSpace throwing translation errors
As these were issues with the system’s code, we reported them to the development team, made sure they were recorded on the ArchivesSpace PivotalTracker page, and waited until the next release before testing again. Given the relatively large number of issues even six months after release, we tested each release thoroughly, pouring through our migrated data once it was in the system; we made sure that everything worked as intended before we went live. This was by far one of the most time-consuming portions of our transition. We created our own personal list of all of our data issues, and made sure to check through them with each test migration, as well as performing a full data quality check specifically looking for any new issues created in the update. We found this repetitive and iterative testing necessary since new issues were sometimes introduced in new releases.
Following a migration, we would export a resource record’s EAD from ArchivesSpace, generally opting to choose a resource record with linked digital objects. Then, we would delete the resource from our ArchivesSpace system, and then import the EAD back into the system. This way we could see if there were any fields that did not export out of the system, or any that would not import into it. This also helped us identify issues like extent type tags with white space crashing the EAD exporter, and is how we learned about the instance container and the accessrestrict notes issues. Our Lead Digital Archivist would then export EAD and test it in our XTF finding aid discovery system to test it for any display issues. Just like the data quality checks, we repeated these processes with each new release, and we continued testing all the way up until the day of announcing a successful migration.
Troubleshooting Errors
We troubleshooted each issue we came across to figure out whether it was active only on our own instance, or present in the migration tools or system code.
When it appeared as if something did not migrate from AT to ArchivesSpace I first checked the backend ArchivesSpace MySQL database table for the missing data. In all cases of data migration, there was a problem with the migration tools, and not the system display settings causing the fields to not display on either the staff or public portions of the site. We then felt confident to report any issues as migration failures, instead of ArchivesSpace system errors.
Testing system issues took more work. I often completely re-installed the ArchivesSpace system, and connected it to the same backend database to make sure that it wasn’t just an issue with my personal installation. I would also shut down the latest instance of the system, and pull up an older release to check whether the new release introduced the issue. If an issue persisted across multiple releases, I checked the PivotalTracker page and made sure the error had actually been reported and that the development team worked on it.
We sent each issue that we found and that no one else had publicly reported directly to the developers and asked them to create a PivotalTracker issue for future development.
Hybrid data and system issues took a little more work. The translation missing and lower case spellings of controlled value list entries errors mentioned above were not an issue with our data or the system, but required correction. To correct this and other smaller issues, I had to delve deep into the frontend ArchivesSpace code. With the help of the ArchivesSpace developer screencasts, I acquainted myself with how to make small changes to the code to support small display and data issues. Fixing the errors required making small changes to a couple of our local enumerations files, but tracking down the correct file and finding the correct sections of code took some time. I had no experience with Ruby on Rails before the project, and I still have almost zero experience with it, but I am now much more familiar with application structure and how to manipulate existing code to do what I want.
In the end, doing test migrations, checking our migrated data, testing system functionality, looking for system errors, and troubleshooting errors was an enormous task. It was by far the most time-intensive portion of the work leading up to going live with the system, but ultimately invaluable; we knew that once we went live, there was no going back.
In the next section, I will write more about the local customizations we installed, tested, and are currently running, as well as writing internal documentation and conducting system training.