One of the components of the new version of DIMES we haven’t written much about is our implementation of International Image Interoperability Framework (IIIF) APIs which support the display of digitized content. This post lays out how we implemented the IIIF Image and Presentation APIs, the decisions we made along the way, and what we learned from the process.
Research
Since we were starting from scratch, we began by doing a fair amount of research. Figuring out where to start, what questions need to be asked, and what decisions need to be made can be pretty daunting. Fortunately, the IIIF community is good about sharing experiences, expertise and tooling. For our purposes, a Code4Lib Journal article by Joshua Gomez, Kevin S. Clarke, Anthony Vuong which describes the architecture and performance of UCLA’s IIIF infrastructure, Tristan Roddis, Rob Lancefield, Jeffrey Campbell, Stefano Cossu, and Neil Hawkins’ presentation “IIIF at Scale” from the Museums and the Web 2020 conference, as well as a highly detailed R&D report written by Stefano Cossu at the Getty were incredibly helpful in grounding our thinking and helping us understand the landscape.
This research indicated that there were three main components we’d need to implement in order to support using a IIIF-compatible image viewer in DIMES:
- An image processing pipeline, to create image files that can be served up by an image server.
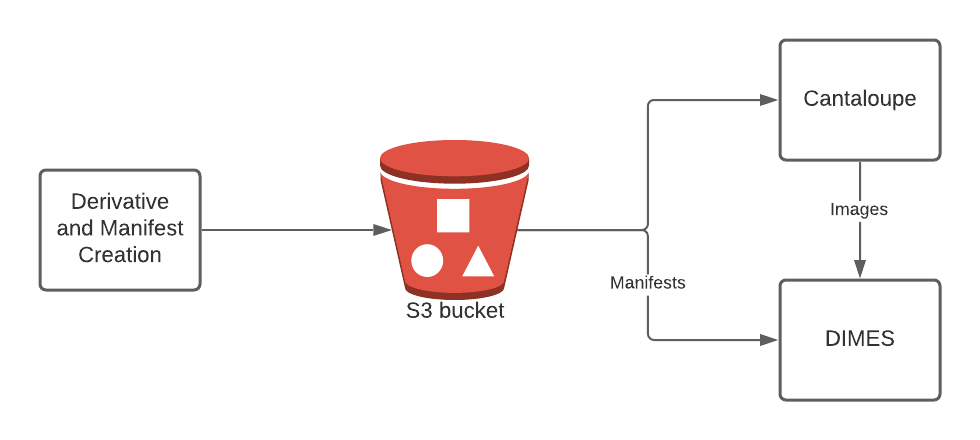
- A manifest creation service to create IIIF manifests which control the display of paged content.
- An image server which supports the IIIF Image API.
It was clear from the outset that, although there were libraries which would help, we’d have to develop the manifest creation service ourselves. As a result, we basically had two choices which paired image formats with image servers: using JPEG2000 with the Cantaloupe image server, or using PTIFF with the IIPImage server. Although the Getty report makes a compelling case for PTIFF/IIPImage being a more performant solution, ultimately we went with JPEG2000 and Cantaloupe because it’s a more commonly implemented pattern, so there’s a larger community base to draw on, and more examples of implementations.
Implementation
Once we’d made decisions about what we wanted to implement, the actual implementation process was fairly straightforward. We implemented most of this infrastructure in AWS:
- We were able to stand up a Cantaloupe server relatively quickly. The main challenge we experienced was connecting our local dev server to the AWS S3 bucket which served up the JPEG2000 images.
- Thanks to a number of examples from places like Stanford, we were able to pretty quickly knock together an image processing pipeline which took our source TIFF files and converted them to JPEG2000 using the OpenJPEG library.
- We were also able to quickly create a manifest creation service, thanks to the iiif-prezi Python library. There was a bit of a learning curve in relation to the IIIF Presentation Manifest, but our implementation is pretty simple and we were able to figure this out quite easily.
Initial batch conversion
Once we’d implemented all of this infrastructure, we needed to batch convert our existing TIFFs, which represented over a decade of digitization work, amounting to almost 400,000 individual pages. This process took longer than expected and required a fair amount of manual intervention, primarily because we had to sort through some performance issues which ate up all available system memory. We also encountered a number of inconsistencies in legacy digitization practices (particularly related to file naming conventions) which required analysis and intervention.
Setting up a service
We’re now in the process of implementing a service which will create image derivatives and IIIF manifests automatically as new content is digitized. This will allow us to incorporate these workflows more fully into the infrastructure we developed for Project Electron, and allow us to more fully leverage the microservices we created there.
Lessons learned and future plans
For me, the speed (this entire process, including research, took about four months) and relative ease with which we were able to implement some really powerful technologies speaks to the importance of community-driven and maintained standards. These standards facilitate shared implementation patterns and common tooling, both of which make getting off the ground much, much easier.
Looking ahead, we’re planning to contribute to the further development of iiif-prezi to help make it compatible with version 3 of the IIIF Presentation API. We’ll also be looking for opportunities to use our IIIF implementation in other web properties.