Over the last few weeks, I’ve been looking into systems which will help us do a better job handling research requests that come in to us via email. You can see what our current workflow looks like in this chart.
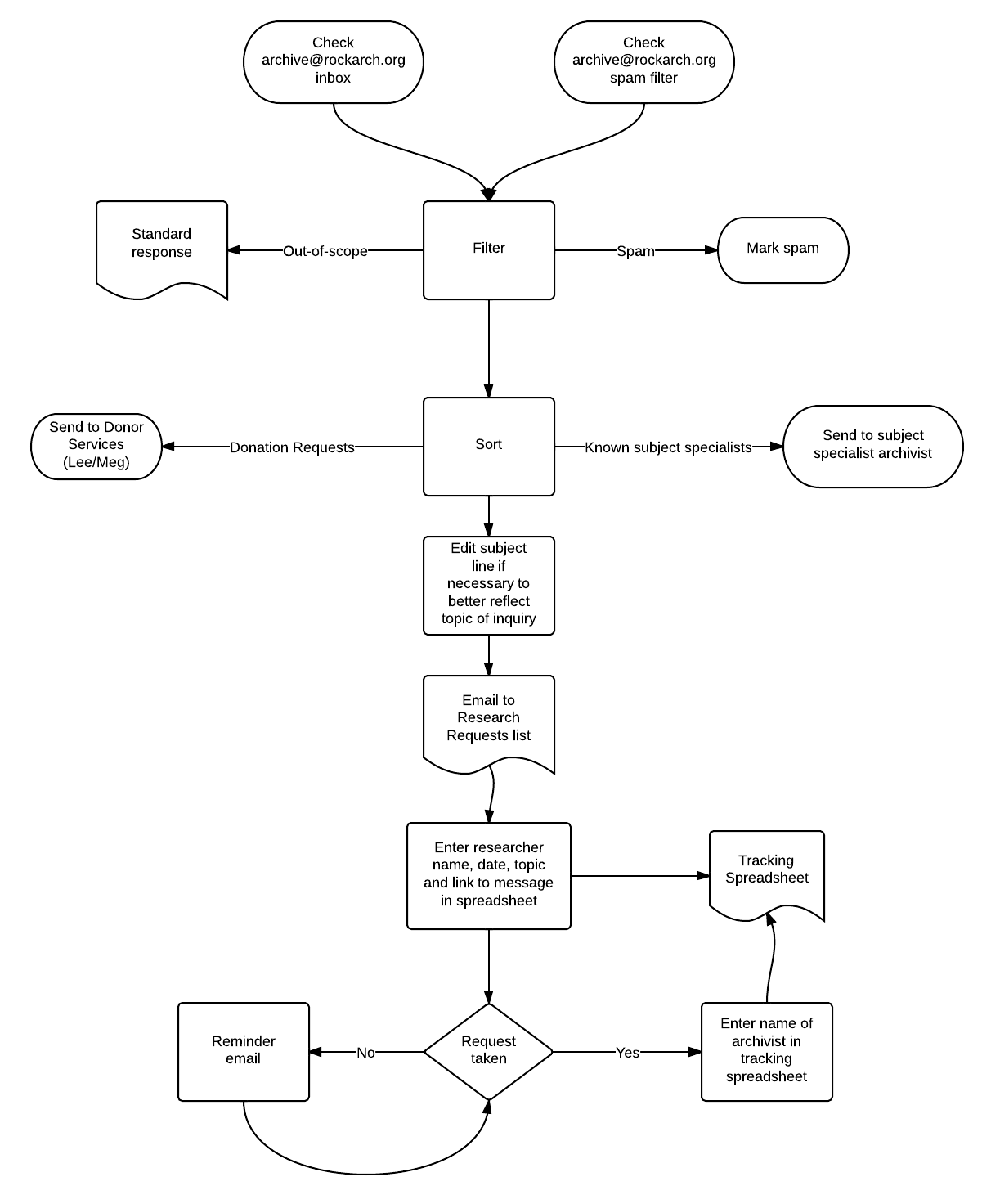
As you can see, a lot of manual effort is required to handle a single request, often including multiple reminder emails if a request isn’t picked up within a few days.
Another problem with our current system is that much of the communication history is missing, since replies are not retained unless a generic email address is Cced on the response. Because of this, as well as the slow response time in searching a huge email database file, finding past communication history that might be helpful in completing a current request is often difficult, if not impossible.
As part of a larger project of looking at technology that will help us to improve our reference services, I’ve been charting out all the processes involved in references, such as the one above. Based on an analysis of these flowcharts, as well as a number of interviews, it became clear that a system which could track research requests, handle request assignment, retain communication history and provide more powerful search and reporting functions would help alleviate many of the problems listed above.
The first thing I did was draw up a list of functional requirements, which included integration with our existing email system, options for assigning requests, the ability to store and send boilerplate responses to requests, and a number of reports we’d like to have the system produce. Based on those requirements, I pulled together a list of around twenty systems – including both open source and proprietary options – and evaluated which best matched our requirements. After eliminating extremely expensive systems, and those which were a poor match for our requirements, I was able to narrow down that list to three choices: RefTracker, a proprietary system from Altarama, Request Tracker, a widely used open source system and osTicket, another popular open source solution.
I then presented those three systems to reference staff, asking for feedback on which system seemed the most appealing. Although reactions were generally positive for all of three systems, osTicket came out as a clear favorite, largely because it had a much cleaner UI than the other two options. Staff also felt that there was a strong correlation between osTicket’s feature set and our requirements; it did what we wanted it to do without a lot of added features or complexity we’d never use.
In the end, although it wasn’t fully articulated in our requirements, perhaps the strongest argument for osTicket was that it didn’t require staff to learn another system or completely alter their workflow. Ultimately, we wanted a system that was invisible in the best sense of that word; one that would do its work in the background and let staff focus on handling research requests without having to deal with menial and repetitive chores.
Although osTicket will require some customization, it’s built on the LAMP stack, which means it will be relatively for us to customize, maintain and support.
Here’s how I think our workflow will look after implementing this system; as you can see, there’s not a lot of change except that a lot of manual intervention has been removed from the equation.
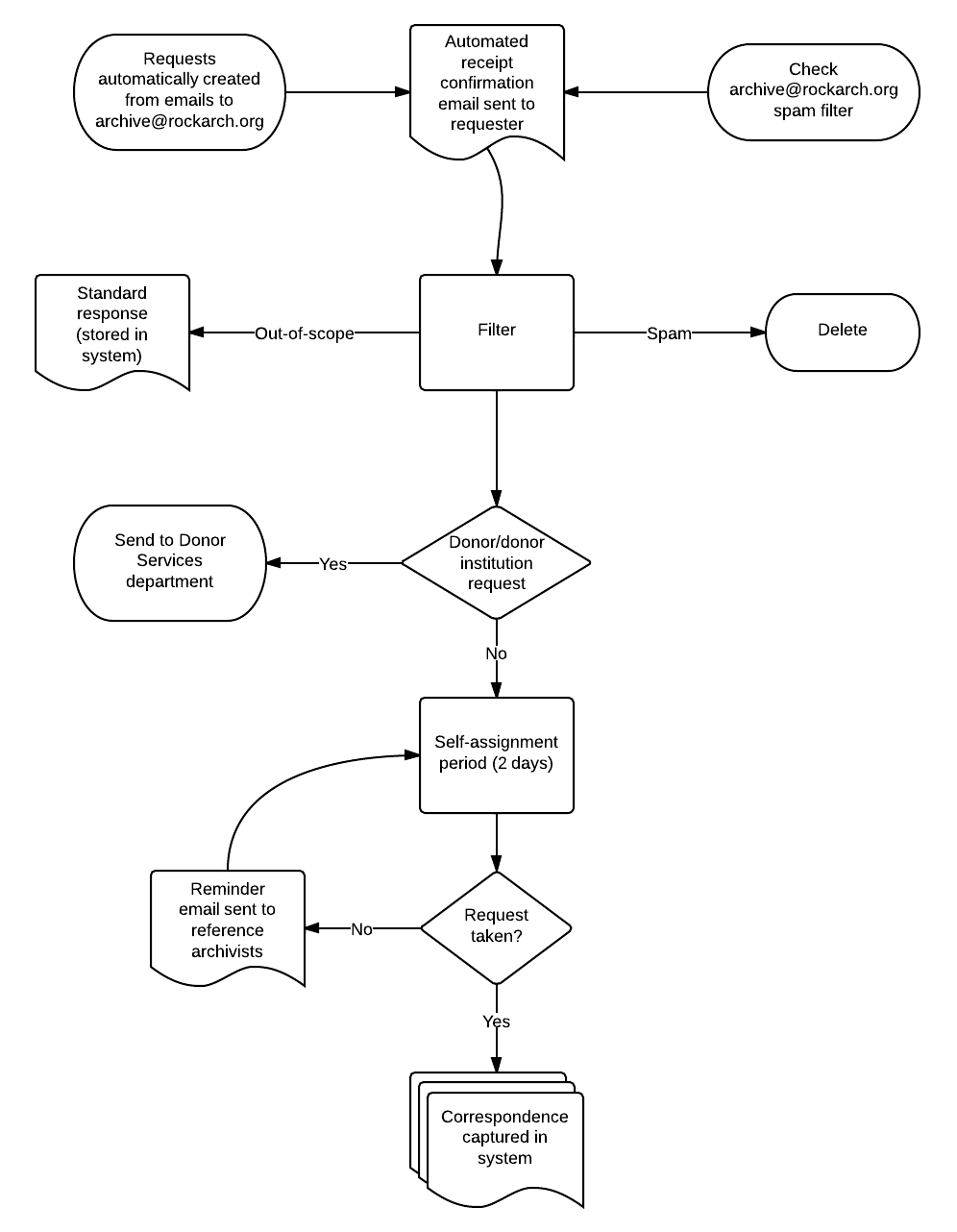
I’ll be working on setting this system up in the next few weeks, so you can expect to see further posts from me as I dig into the system.