Today we’re announcing a major project to build sustainable, user-centered and standards-compliant infrastructure to support the ongoing acquisition, management and preservation of digital records so we can make them available in the broadest and most equitable way possible. Because a snappy title makes everything better, we’ve codenamed this effort Project Electron, and we even have a cool mascot (Captain Electron, discovered by our internet expert Patrick Galligan):

The project will consist of a repository, which will store digital records as well as information about them (including archival description, technical metadata and preservation metadata) which will help us manage and provide access to them over time. Sitting on top of that, we’ll have an API layer which will help us manage system interactions between the repository and other archival systems which assist in processes such as accessioning, description, and access.
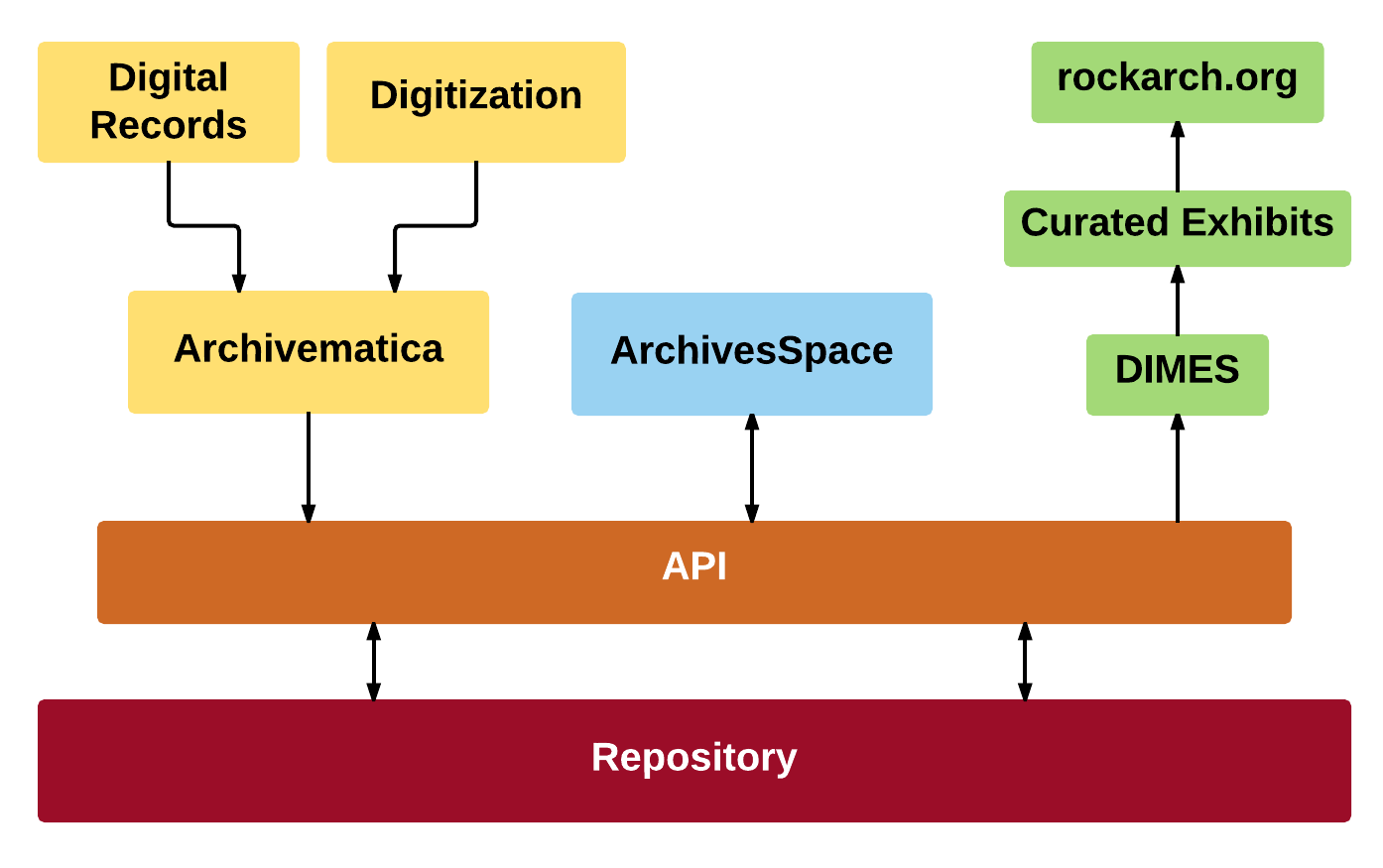
We have an official press release out today, but I wanted to emphasize a few things in a less formal way. First, we’re not going this alone. We’ve developed a partnership with the talented folks at Marist College IT to provide us with the technical infrastructure and expertise to pull this off. And we’re leaning on the expertise and generosity of so many people who have offered us their time to help us think through different aspects of this project: Erin O’Meara, Mark Matienzo, Karen Estlund, Keith Oberlin, Lauren Philson, Jason Varghese, Shawn Averkamp, Julie Shean, Kirsten Carter, Sally Vermaaten, Mike Shallcross, Dallas Pillen, Max Eckard, Camille Salas, Mike Giarlo, Ben Armintor, Rob Sanderson, and of course Sibyl Schaefer.
Second, as we kick off this project we want to focus not just on what it will do, but more importantly the values we want it to embody. A few months back we drew up a list of four values (plus some explanations) to help guide our thinking about design and implementation decisions. We consider this a living document and, like the rest of this project, we’ll make it publicly available using version control software sometime in the near future when we have those details hammered out.
Create reproducible and modular deliverables
So that our work has the broadest possible impact, the components of Project Electron will be built using open-source technologies and will be comprehensively documented so they can be easily implemented by other institutions. We will use “stopwatch metrics” to measure our progress towards creating software that is easy to deploy. Components should be modular and generalizable; to the greatest extent possible their deployment should be independent of other systems and flexible enough to accommodate integration with changing systems.
Place users at the center of the design process
In order to produce tools that are empowering, engaging, transparent and robust, we will employ user-centered design methodologies to define user communities - including Rockefeller Archive Center staff, on-site and remote researchers, donor organizations and individual donors - to understand their needs. We will seek to implement constraints and affordances to the user’s benefit, assigning repetitive, detailed and time-consuming work to machines while enabling humans to exercise their critical thinking skills to full capacity. We will provide solutions to support donors and donor organizations with a wide range of technical expertise while protecting our researchers’ privacy by limiting collection and retention of personally identifying information and anonymizing data used for analysis.
Support archival practices and standards
The project deliverables will maintain compatibility with existing standards for data content and structure, and will support established archival processes for accessioning/ingest, arrangement and description, discovery and access, and long-term preservation. The project will support best practices before edge cases, focusing on central use cases while accommodating edge cases when possible.
Support data in motion
Rather than seeking the unattainable goal of completely centralized or deduplicated data, we recognize that not only is duplicate and distributed data a reality of our networked world, it is also a desirable outcome for an organization whose mission includes broad dissemination of knowledge. As a result, we will think about systems as points at which humans interact with or manage data rather than canonical sources of data, and the underlying API and business logic that syncs data between systems as a platform on which access and use services can be built. In addition to facilitating data flow between internal systems, we also want to accommodate systems external to the Rockefeller Archive Center.
We’re really excited to be embarking on this project, and we hope you all come along with us! We’ll be posting about this a lot more in the coming months and years, so stay tuned to this channel to hear more. If you’re on Twitter, you can also follow us at @rockarch_org for real-time updates.