We’ve been doing a lot of technological systems work at the Archive Center over the past few years; we’ve been standing up and migrating to new systems, tweaking and refining existing systems, and developing entirely new services to help with everyday work. We’ve recently kicked off a systems infrastructure audit project that aims to help us understand our systems better and make improvements on how we develop, deploy, and maintain our archival systems. This blog posts aims to provide some background for why we took a close look at all of our systems, both in production and development, and lays out some findings from our systems audit, and some of the general talking points that we posed to ourselves in trying to figure out a way forward. Hopefully, our experiences will help others in the same situation figure out what questions they should be asking of themselves.
As part of the audit project, I put together a systems information spreadsheet that aimed to gather data about all of our in-use systems. This spreadsheet aims to serve as a single compiled source of information about all of our systems outside of our separate systems information sheets. Each system has a column for: the distribution and version of the deployment server OS, development server information, system update responsibility (hosted or in-house), update frequency, system framework, system components (frontend, backend database, etc.), documentation, and expected frequency of use. We also gathered information about when we implemented a system and which systems we viewed as temporary and which systems we expect to fulfill the business needs for in the near future.
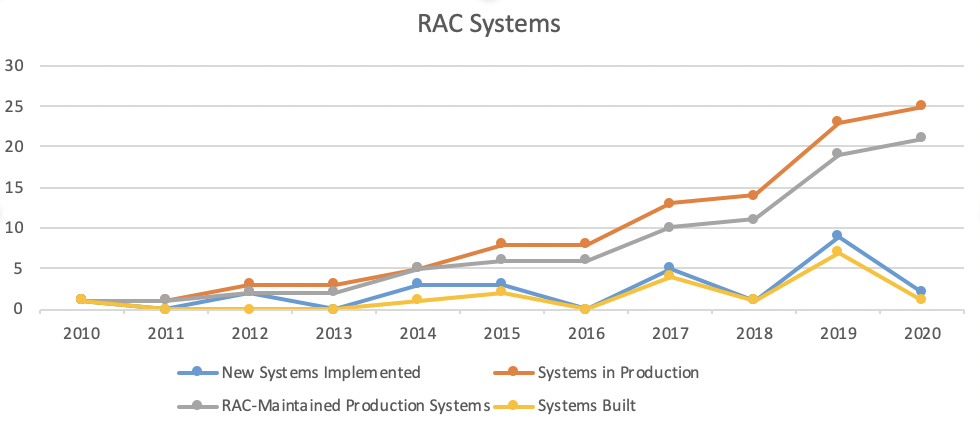
Before I get into the specifics of the data gathering, it might be helpful to give some background on the size of our teams that make systems work part of their purview. We have two full-time IT professionals and the Digital Projects Team has had four members fairly steadily since 2013. In 2010, the Rockefeller Archive Center had a total of two archival systems in production. In 2020, we have at least twenty-five core systems that directly relate to archival work. The Archive Center directly maintains the installations of 18 of these systems either on-site or through AWS. Between 2018 and 2019, the RAC implemented eight new systems or services. It became painfully clear that we were heading towards a tipping point where our old systems development, deployment, and maintenance approach would no longer work for us. We needed to spend time thinking about ways to level up our workflows and how to work with our systems more efficiently.
Coming out of the data gathering, I tried to synthesize what I was seeing about our systems into general talking points for a future team meeting about the results of the survey. I broke the talking points into three general sections of questions and talking points: Systems in Production, Server Infrastructure, and Systems Maintenance. Below are some of the most salient questions and talking points.
- Systems in Production
- How can we generally improve our management of our systems?
- Are there opportunities to collaborate more effectively with IT?
- Server Updates and Distribution
- How can we better stay on top of updating our production and development servers?
- Whose responsibility should it be to keep on top of distribution and package updates and management?
- Is Continuous Deployment a useful pattern for us?
- Systems Maintenance
- What are our current systems maintenance practices? Do they exist in a codified form?
- Where are the current systems/application management breakdowns?
The D-Team had a lively discussion that ran for almost two hours just trying to unpack what we were currently doing and what we saw as the next steps forward. Perhaps unsurprisingly to those with systems experience, we identified dependency management and updates as one of our most time-consuming, manual, and frustrating operations. We have so many different applications that use a multitude of different packages that just making sure all of the packages stay up to date is a time-consuming task right now. Additionally, we’re somewhat caught between two worlds: our newer, internally-developed systems have good test coverage and we’ve been moving towards Docker containers for deployment, but our procedures for older systems and applications often fall short.
We think we could lessen some of these pains by moving iteratively towards Continuous Integration (CI) and Continuous Deployment (CD) processes, but we need to get a better understanding of what we’re already doing and how that would fit into future pipelines first. In order to move towards more comprehensive CI/CD practices, we’ll also need better automated test coverage on all of our systems, systems resource tracking, some form of logging analysis, and SSH key management. We could also go back and start containerizing all of our older applications so that they will be easier to redeploy when necessary. We’re in the early stages of exploring tools to help us take our pipelines to the next stage, but we’re open to suggestions, so if you have experience in doing this at a cultural heritage institution, we’d love to hear about it!
If that seems like a lot, it’s because it is. We’ve got a long way to go to get to a place where we feel completely comfortable with our systems development, deployment and maintenance processes, but gathering so much information about our systems allowed us to see how far we’ve come and what we still need to work on; it was both an enlightening and sobering experience. It’s fair to say that we already had an inkling of some of the issues that we were facing before performing our systems audit, hence the larger systems sustainability project, but the act of gathering information on all of our systems gave us an opportunity to take an in-depth look at our current workflows and how they are no longer working for us.
Working with systems is a lot like gardening. It feels great to plant those seeds and see the first little shoots pop out of the ground, eventually your plant starts bearing fruit, but it’s a lot of work to keep the plant alive, blossoming, and manageable. You have to keep watering your plants, make sure they’re in the right size plot, feed them regularly, change the soil, and occasionally weed or prune to promote healthy new growth. It takes attention and maintenance to keep your services running; a concept that might have been novel to me five years ago, but that has become increasingly clear as we’ve started adding more plants to our ecosystem. This project has been a vital reminder that while it’s important to implement tools to improve overall quality of life and work, we can’t forget to maintain our foundation or else we risk not being able to support all that we’ve built.
As always, I’m happy to chat with others that are interested in this topic. We are extreme neophytes in regards to CI/CD, so any stories and experiences would prove valuable.