Beginning in 2011, the Rockefeller Archive Center accepted the records of the Ford Foundation, and included among these papers were records pertaining to Unpublished Reports and Grants from the Foundation’s inception to the present. Along with the materials, the Ford Foundation provided us with two spreadsheets filled with metadata describing both the Unpublished Reports and Grants files. The Grants file alone includes 54,644 rows and 34 columns of information ranging from subjects terms to restriction information. However, much of this data was “dirty”; many subject terms did not match LCSH vocabulary, dates did not match formatting for import into Archivist’s Toolkit, and many more issues. Despite these issues, the metadata opened new avenues of access and description to the materials, and wrangling and refining them for import into Archivist’s Toolkit and DIMES would help researchers from all over the world discover the exact item he or she is looking for. In November of 2013, members of the Digital Projects team met with representatives from Processing and Reference with the express goal of transforming this metadata into a machine-readable format so that the RAC may provide it in a searchable format online.
Coming out of this meeting, we had a plan and a tentative map about how we could work together to refine, map, and transform the data in the spreadsheet into an EAD document ready to import into AT. Before we began transforming the data into EAD, the committee met and agreed upon how to map the metadata into EAD. The overall consensus was to include anything that could be a controlled vocabulary term, like author, subject, or grant location, as different types of subjects, and all other information would be instance types, dates, or internal and external notes.
Given the volume of metadata, I needed a method to work with and manipulate the spreadsheets en masse, so I chose Open Refine as it is a free platform specifically designed for working with lots of data. Furthermore, using Open Refine would allow me to work with the LCSH reconciliation tool provided by Free Your Metadata. Before reconciling the data, I split all multi-valued cells based upon the semi-colons that Ford used to designate the end of one value and the start of another. After splitting the values, I used Open Refine’s built in ability to cluster and edit data to correct any casing, spacing, and spelling using the nearest neighbor, which created a more standardized dataset and removed any variations in the controlled vocabulary.
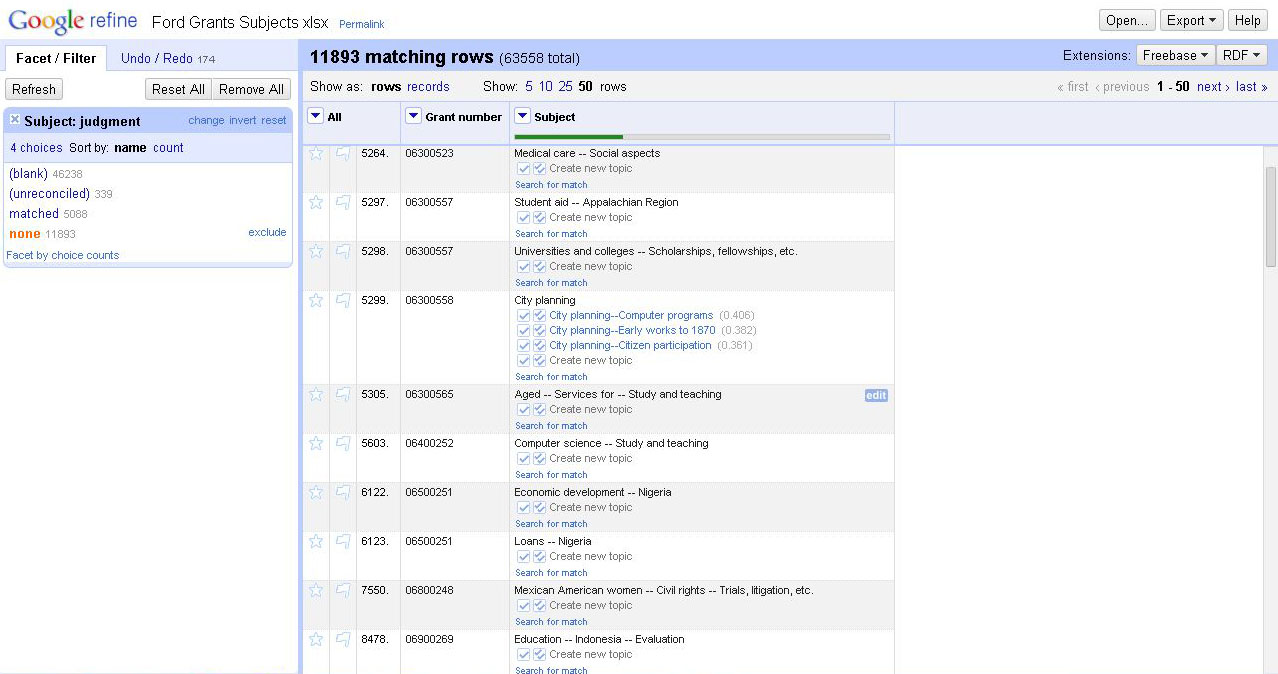
After cleaning and standardizing the metadata, I installed an RDF extension from Free Your Meatadata that interacts with Open Refine, which lets you select a digitally-available metadata and check your data categories against all of its entries. Given our needs, and its availability through a SPARQL (a query language that can retrieve data stored in an RDF framework) endpoint, I chose to reconcile the provided topical terms against LCSH. After running the reconciliation, Open Refine will provide a list of facets with matching category assignments or unreconciled terms. At first, the service was only able to match 25% of the terms with LCSH, but, after manually reconciling a number of terms that only differed from LCSH by small amounts, I was able to get the automatic reconciliation of topical terms to about 30%. Correcting the remaining 70% would require individual checking of each term, which would be too prohibitive given the project’s timeframe.
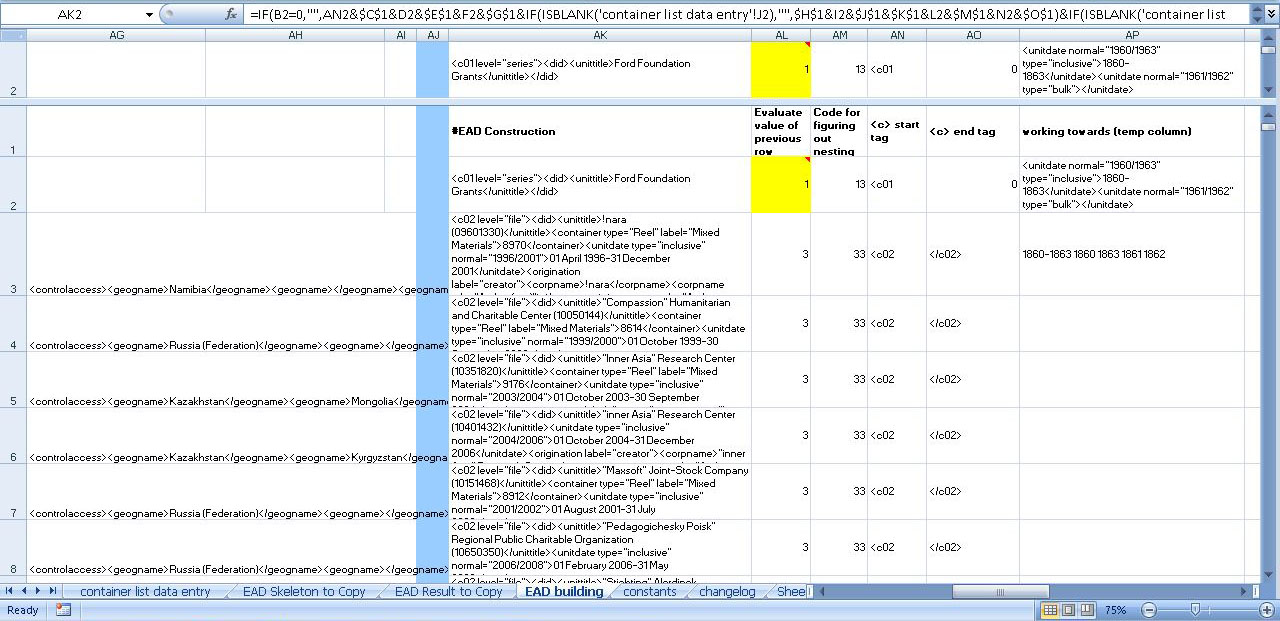
Following the reconciliation of the subject terms, I had to export the information out of Open Refine and transform the Excel data into EAD. For this task, I repurposed an EAD data entry Excel template created by Matt Herbison of Drexel University based upon an NYU design that originally made container lists and EAD dates from Excel tabs. Unfortunately, the original NYU spreadsheet is no longer available online, but you can view the project information here. I added various EAD headings in formulas, and made it so we could copy and paste metadata straight from a worksheet into another worksheet, which would later wrap the data in the necessary EAD elements. Afterwards, Excel formulas would add the different elements together inside of the appropriate container level based upon the entered data. From there it was simply a matter of copying and pasting the provided EAD from the Excel document into a standard XML editor; there were various errors due to some data conversion techniques, but some simple find and replace operations managed to fix those.
Ultimately, the reconciliation effort, while admirable, did not provide a high enough level of data clean-up, and we would like to clean even more of the subject terms before ingesting the record groups into AT, but we are in place to import the EAD as soon as we can come up with a workable solution for cleaning the rest of the subject terms.