As our work on the transfer application portion of Project Electron nears its completion, I’ve started to think more seriously about modeling our data that we are bringing into our systems. We’ve actually been prepping for this stage of the project for months, going all the way back to the Data Model Bibliography I put together in February 2017. Now that the D-Team was in the thick of data modeling, we thought it was time to bring the rest of the Archive Center on board as well. I’m just a single archivist, and even though I’ve done a lot of reading about data models, I’m no expert on the entirety of our collection or its materials. We knew that we’d need more eyes on our initial data model draft once we made it to make sure we weren’t forgetting an important component of our collections.
However, as anyone that’s worked with data models might know, they can look extremely intimidating to an untrained eye, which acts as a barrier to constructive feedback. So, how do we break down these walls and make data models and modeling more accessible to a wider audience? Our answer was to hold two separate “Data Modeling 101” workshops open to any staff members. Right off the bat, I need to give tons of credit to Hector Correa, Christina Harlow, Mark Matienzo, and Steve van Tuyl. I attended two data modeling workshops at Code4Lib 2017 that this fabulous group put together, and I leaned heavily on their past work in developing slides and activities.
These workshops were really crash courses in the concept and philosophy behind data modeling, and only barely dipped into the technical aspect of modeling. We were also trying to avoid too many details about RDF, but a lot of our examples were based on semantic modeling. We had great turnouts to both sessions, and in the end, about 25 different people on staff attended at least one of the sessions. Each session was about 2 hours long, and I knew that was a long time to ask anyone to sit quietly and listen to me talk about somewhat abstract and complex concepts, so I tried to include a few group or participatory activities, which attendees responded favorably to.
We started out with an exercise in recognizing the essential characteristics of wine, an idea I cribbed from “Ontology 101: A Guide to Creating Your First Onotology”. Wine seemed like a perfect choice because it’s so ingrained into our society’s zeitgeist that even if you’re not a wine drinker or fan, you probably know something about it. Additionally, I wanted to start with a non-library or archives related example to illustrate that modeling can be fun and can apply to literally anything. The wine exercise proved extremely successful and got people to participate quickly.
Next, the groups took a prose description of needs for a digital repository and broke it out into attributes, types, objects, classes, and functions. I took this exercise directly from the C4L data modeling course, and it worked wonders in explaining the differences between the different types of objects in a data model. Using confusing terminology like this is about as technical as these workshops got, but I think they were still successful in getting coworkers invested in the process and granting them a little more understanding of the work that I’m currently doing.
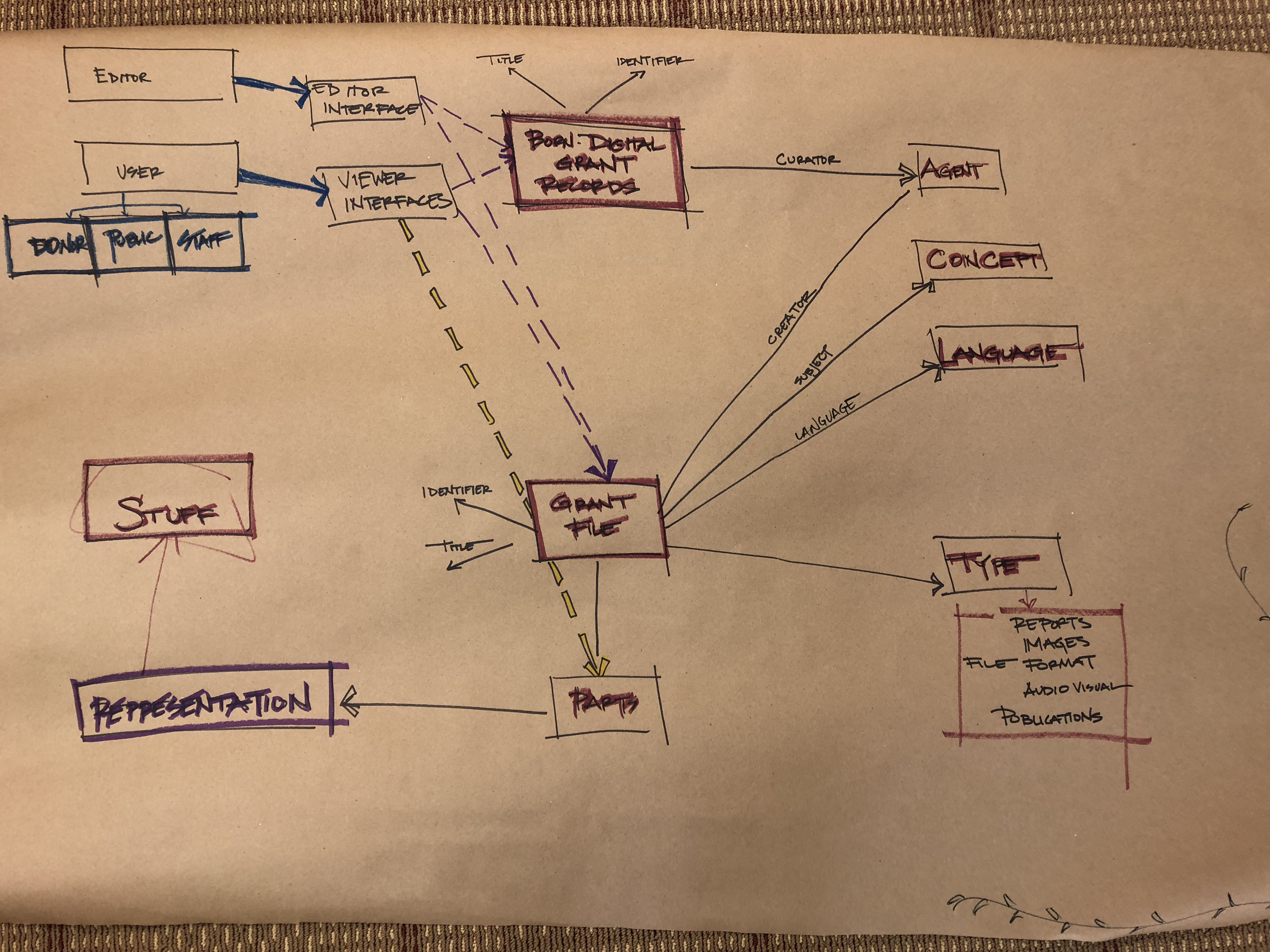
We finished off the workshops with a group data model diagramming activity. Each workshop split into three groups, chose a sample object, and tried to draw a model of it within a digital repository. I’ve posted three of these in this blog, and while these are first attempts at diagramming and will not be used for the overall model, I think they are admirable for groups that had no idea what a data model was 90 minutes earlier.
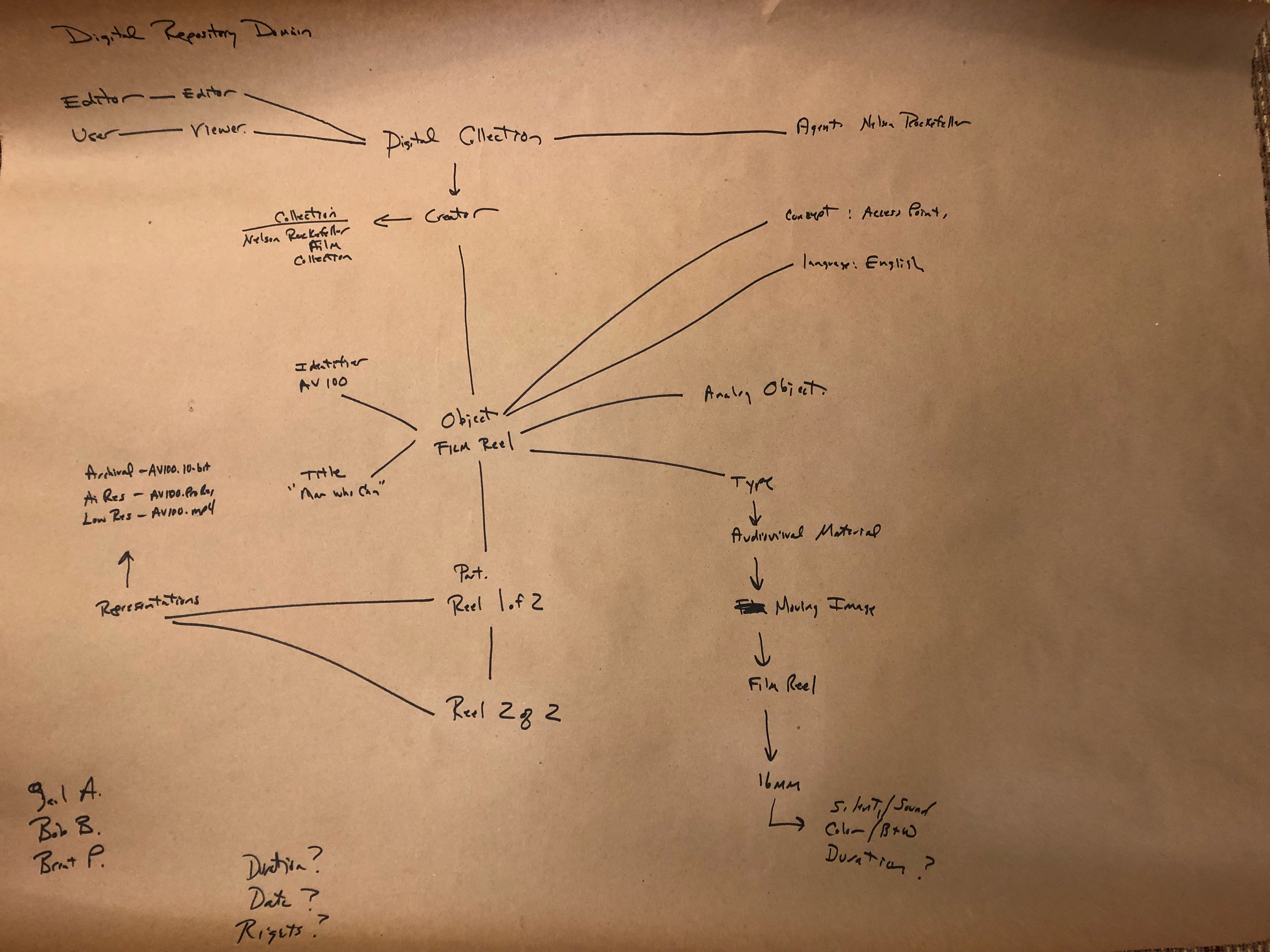
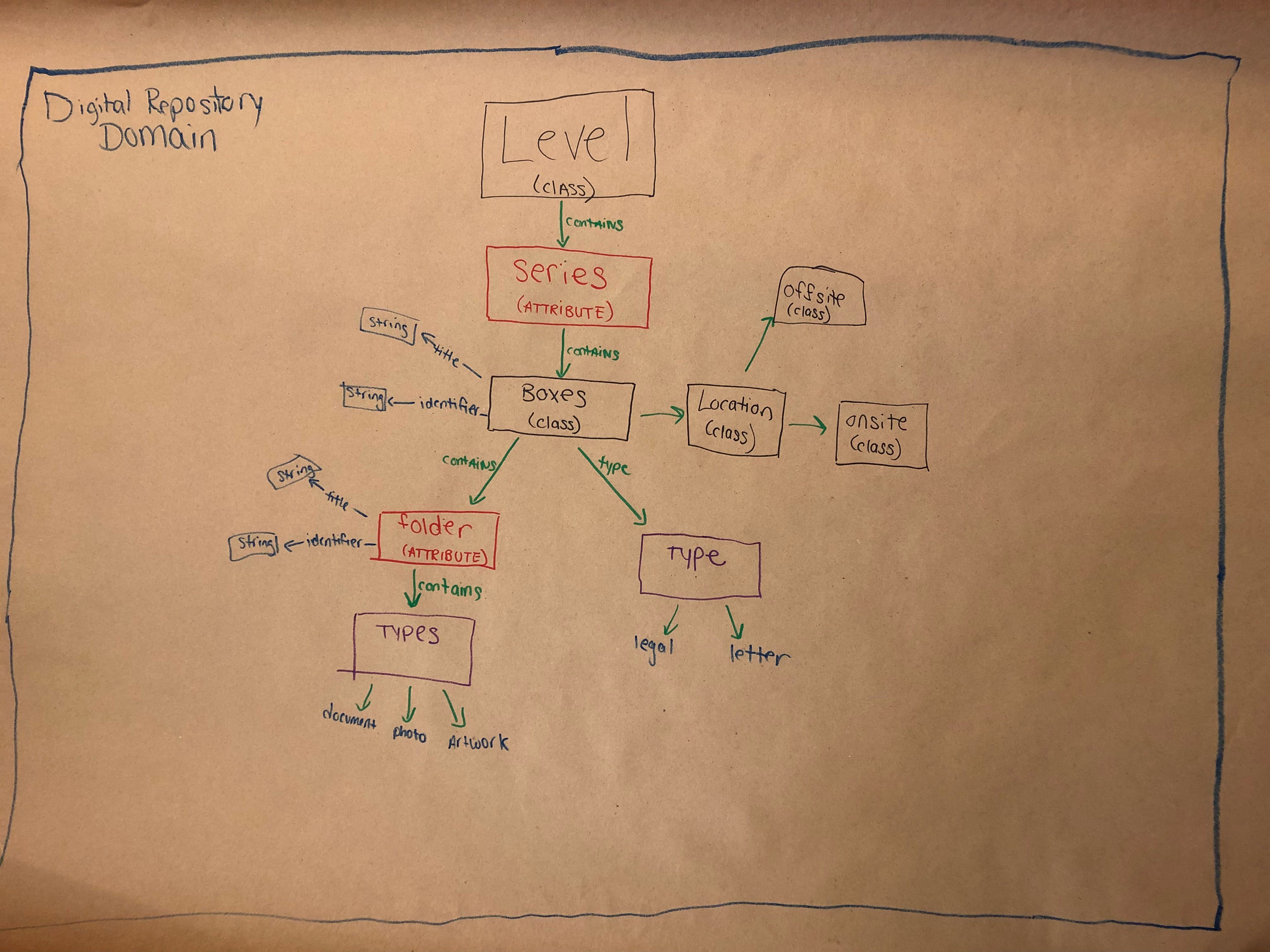
With the changes to the types of records that libraries and archives collect, data modeling is becoming a core concept for many in our field. It’s scary and intimidating to think about at first, but if you were to take anything from our data model workshopping experience, it’s that anyone can learn to think with a data model mindset. Modeling is a skill that has to be learned, like any other, but it’s not one that’s so specialized that a processing archivist, reference archivist, or really anyone couldn’t it pick up. If I can learn it, anyone can.