Over the weekend, we finished up a year-long project to import description for almost every single grant record the Ford Foundation ever gave. This is the same project that I wrote a post about last October. To refresh your memory, we started with 54,644 grant files described in an Excel spreadsheet, and we wanted to transform much of that data into EAD, and then import it into ArchivesSpace. Normally this project wouldn’t require an entire year, but we realized over the course of the project that we did not have efficient ways to reconcile our structured data against Library of Congress vocabularies. The post in October laid out our methods for reconciling subjects against LoC data; this post will detail the methods we took to reconcile corporate names against the LCNAF.
Before I could start reconciling data, I created a list of unique corporate names in our dataset. Given that the data started in a spreadsheet, I could easily use Excel’s pivot table functionality to create an alphabetical list where each corporate name only appears once. We now had a list of 14,698 total corporate names that we wanted to check against LCNAF structured data and we were ready to try to start reconciling these names against a structured data source. Unfortunately, we couldn’t use our previous method described at Free Your Metadata (freeyourmetadata.org) because they did not have a reconciliation service set up for name entities. Our first instinct was to try to duplicate the Free Your Metadata process by setting up a Virtuoso server running SPARQL. We could then load the LCNAF RDF data available from the LoC downloads, but we lacked any experience with those systems. Looking for any other way to reconcile these names without manually checking each one, we turned to the Code4Lib listserv for ideas.
We got many great ideas from the list, but the one we eventually went with came from Matt Carruthers at the University of Michigan Library. He wrote JSON code for use with OpenRefine that searches the VIAF API first, limiting results to anything that is a corporate name and has an LC source authority. OpenRefine then extracts the LCCN and puts that through the LCNAF API that OCLC has to get the name. In the end, you get the LC name authority that corresponds to your search term and a link to the authority on the LC Authorities website. Any items without a match in the LCNAF dataset will not have a link.
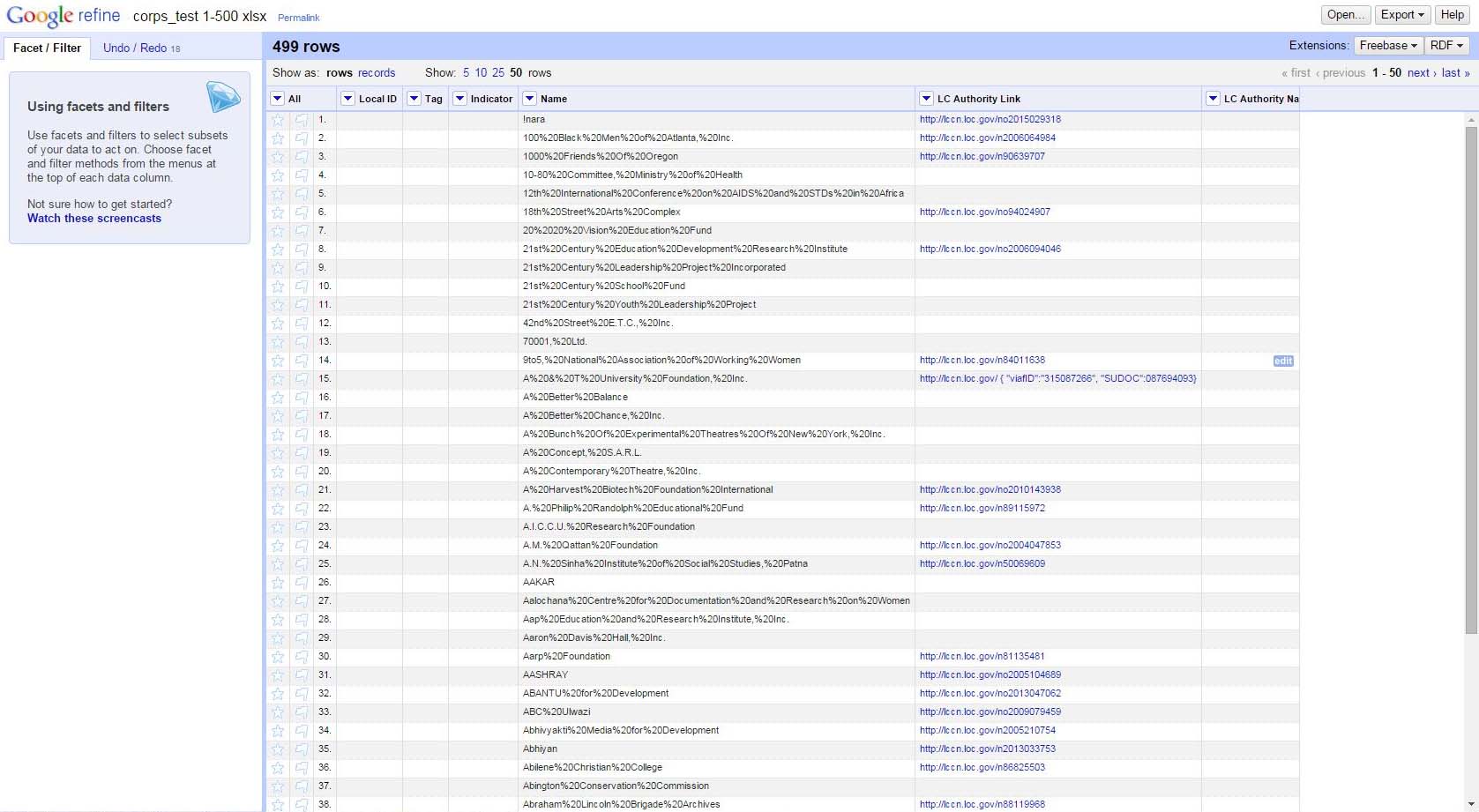
Before import you also have to replace all white spaces in your files with %20. Caveat emptor: the system is not 100% accurate, and can return some false positives, so manual QC will be necessary if you want to remove all errors. Unfortunately, it also only works at about 500 names at a time and takes 10 to 15 minutes to run through each set of 500. We split the corporate names into 29 separate excel tabs, imported them each into OpenRefine, ran the JSON reconciliation script, exported all of the results, and then reconstituted them into a single document. I performed a metadata quality check of about 5% of the names, and most of them checked out. A few were obviously false positives, but not enough to make me lose confidence in the methodology.
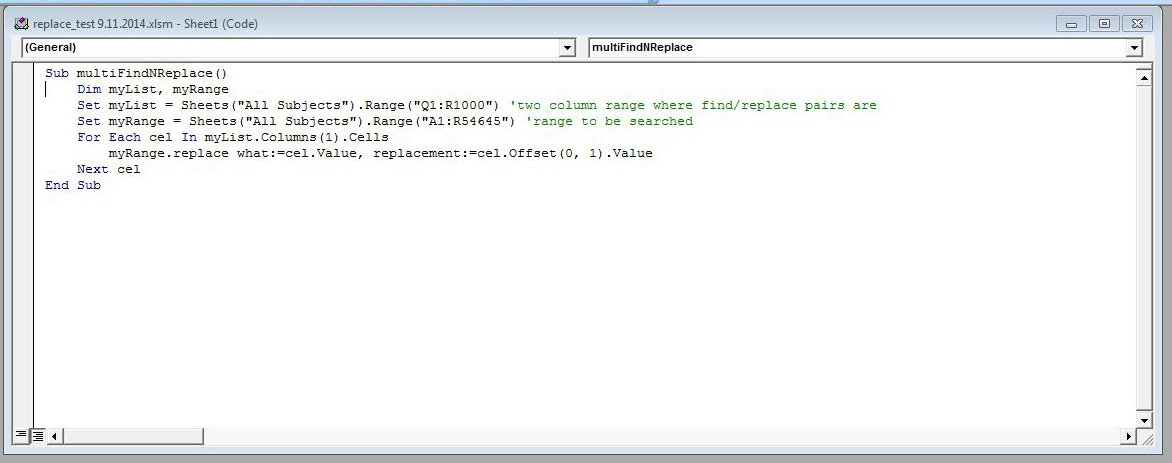
After getting a full list of all corporate names, we appended either <corpname role="aut" source="local"> or <corpname role="aut" source="lcnaf"> to the front of each name identity and replaced all of the %20s with a space, and then appended </corpname> to the end of the name. We now had a fully identified list of which names were local or LCNAF verified. Using the same find and replace script from the subject cleanup, we replaced the modified corporate names in the original document.
We would still like to explore the possibilities of using Virtuoso and SPARQL in the future, but given the time sensitive nature of our project, we needed a quick and dirty way to get our information online. Ultimately, the entire Ford Foundation records, Grant Files EAD equaled 66.6 mb of data, which we had to split up into 11 different resource records because ArchivesSpace could not handle a single resource that large. We also had to tweak the backend code of ArchivesSpace’s EAD converter in order for it to automatically publish notes not marked internal in the EAD, but that was only about 5 to 10 hours of work and testing.
You can find the end product in DIMES.