As Hannah indicated in her last blog post, we’ve been thinking a lot about the next phase of Project Electron which, broadly speaking, looks at how researchers (and other user communities) find and get access to all the great digital records we’ll be transferring from our donor organizations.
As with the rest of this project, we want to be conscious of existing tools and practices so we can build on what’s working well and try to improve what isn’t. This is a major reason we started by reviewing our personas and user stories. Hannah’s blog post does a great job of summarizing what we learned during that process, and I won’t repeat all of that here, other than to say that the challenges faced by our users in finding and accessing archival records need to be addressed holistically. In other words, considering access to digital records separately from access to physical records is akin to looking only at part of a large picture; on the other hand, considering user needs across formats is a useful way for us to focus on the qualities of the user experience we hope to provide for our researchers.
Goals
We have four main goals for the next phase of Project Electron, which have come out of a fair amount of reflection and conversation among the project team as well as staff throughout the RAC:
- Improve the user experience: we want to allow users to browse browse archival relationships between groups of records, agents and subjects in a fast, device-responsive and visually appealing interface which complies with WCAG 2.0 level AA criteria. We also hope to provide support for the RAC data model, which represents the archival description generated by our workflows more fully and accurately than individual finding aids.
- Improve system reliability: by improving the logging and failure recovery of processes which fetch, transform, and index data we hope to ensure that archival description in our discovery environment is always up to date. We also want to reduce reliance on data formats with a high serialization overhead.
- Allow for use of external data sources: recognizing that archival description is part of a web of interconnected data, we plan to pull data from external sources (such as Wikipedia and Wikidata) while ensuring those processes are scalable, sustainable and appropriately configured for our users.
- Separate discovery and delivery layers: in order to support delivery of a wide variety of digitized and born-digital content, and to allow for better access controls, we plan to differentiate between discovery (“Can I find this thing”) and delivery (“Can I see this thing”) both in terms of planning but also systems architecture.
System components
I started to write a paragraph explaining our proposed architecture, but then I realized I could just show you a picture (please keep in mind this is all subject to change, I’m going to be just as amused as you when I come back and look at this in a couple of months):
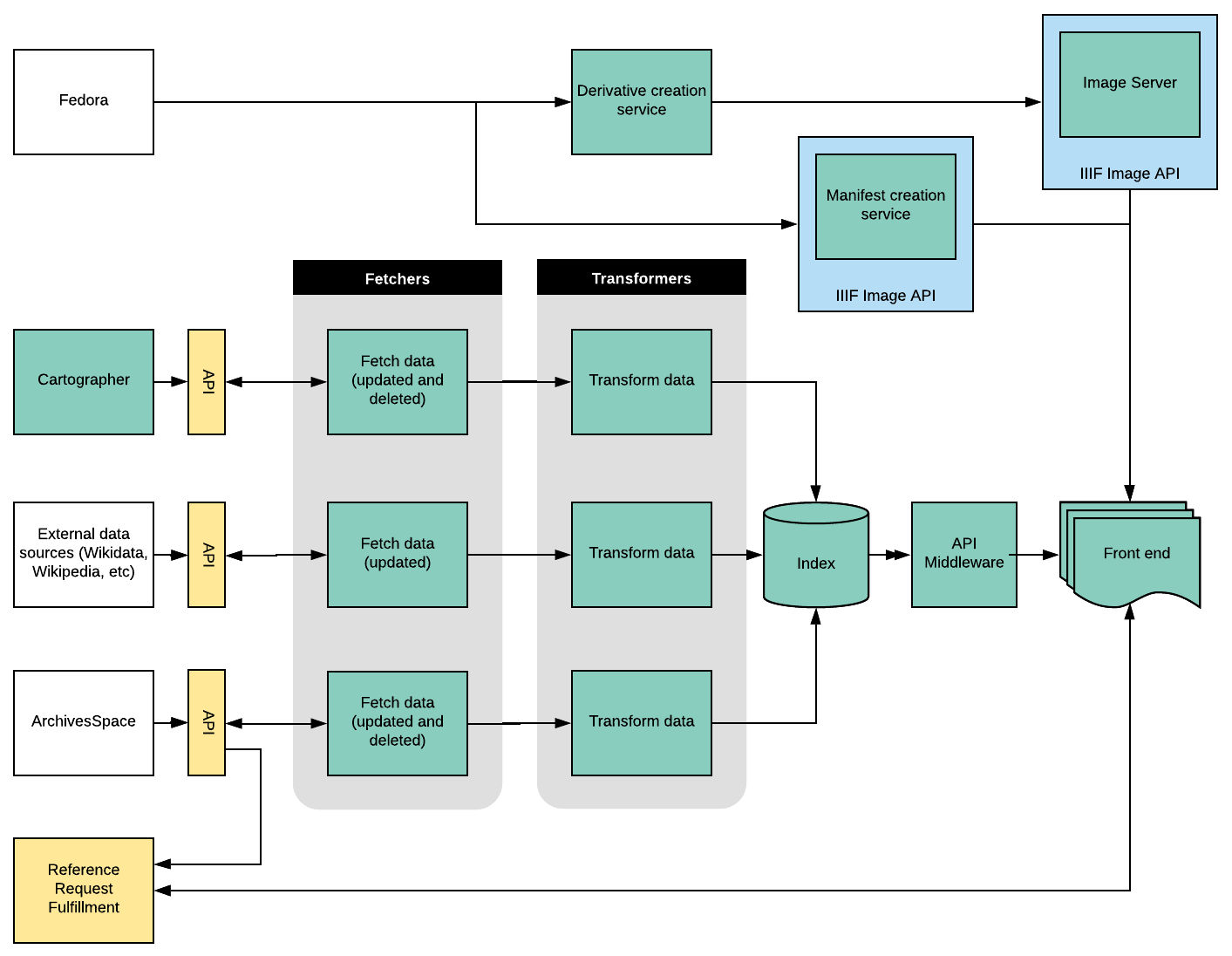
There’s a lot to this architecture, and working on it all at once seemed daunting. So we’ve decided to break this into two pieces: first we’ll focus on developing an interface for users to search, browse, and view archival description, and then we’ll integrate digitized and born-digital content into that interface.
There are basically three major components of this architecture that support our first milestone of creating an interface for archival description.
- Data pipelines, or sets of services between data sources and an index. Each pipeline has three main services:
- Fetchers, which get new or updated data from a specific data source. Fetch services run independently of one another, and can be deactivated or implemented without impacting other fetchers.
- Transformers, which accept data from a fetch service and map it to a predefined output.
- Indexers, which take the data produced by transformers and add, update or delete it in an index.
- API middleware, which formats data from the index into a standardized structure to be used by clients. This allows us to decouple the index from interfaces, and creates a stable representation of all our public archival description.
- A frontend will provide a user interface to support searching and browsing of archival description, and eventually to facilitate viewing of digitized and born-digital records.
Each of these three components is worth a blog post in and of itself, so stay tuned in the coming weeks and months as we roll those out. In the meantime, if any of this looks interesting or sparks questions, please feel free to reach out and let us know. We’ll be sure to update as we continue on the Project Electron voyage.