For many archives, the master shelf list has been a permanent staple since their inception. We have one. It’s an ever-growing Excel spreadsheet that lists the location of every single box in our collection down to the shelf number. It’s enormous, it’s unwieldy, and it takes a ton of work to keep updated month to month. For years we’ve been looking for a way to move away from it, and the release of ArchivesSpace version 1.5 has given us the rare opportunity to move entirely away from our spreadsheet into a more structured and interoperable. The Rockefeller Archive Center will no longer enter new information into our Master Shelf List.
Our Collections Management team has embarked on a major project to accurately describe all of its containers and locations in ArchivesSpace over the next two years; they are tirelessly entering heaps of data into ArchivesSpace top containers, dedicated to making AS the system of record for all location information. It’s great that we’re getting all of that data out of Excel and connected to our description, but where does that leave our staff when they actually try to find a box in our collection? Do they have to open up AS, find the component, open up the top container, and then get the location for each box they pull? How do they then get this information into Aeon (the system we use to track materials as they move from the stacks to different areas in our building) for request tracking? Doing that for every box seemed like an unnecessary complexity for us, and the AS API allows us to easily mitigate this complexity by interacting with the AS data in different ways.
We thought the best solution to avoid multiple clicks in AS would be to build a web application that can pull JSON data directly from ArchivesSpace and display it in your web browser for easy copy/paste operations. So we made what we’re calling FindIt).
FindIt is a single-page application that fetches JSON information about archival objects in ArchivesSpace using refids. Our Aeon installation automatically includes an ArchivesSpace refid and a link to each requested object in our discovery system, and an RAC staff member can take either this link or a refid and drop it into the FindIt search box to quickly display a location that they can then copy and save back in Aeon. FindIt works by quickly searching through all refids in the ArchivesSpace application, and then works backwards to grab the archival object title, container information, and location information. It also provides a link back to the archival object in your Archivesspace installation.
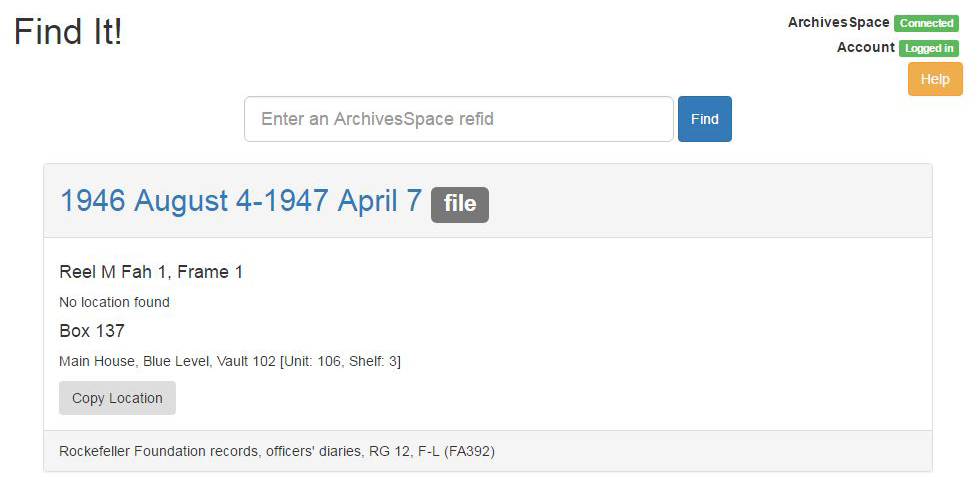
We have made a few assumptions for this work, the primary ones are that our users would want something simple that only had a single use. We wanted to build something that anyone on our staff could use with little to no training; anyone that has used Google could probably use FindIt. There’s nowhere to get lost on the page, and we like that. As of writing this post, there application only returns results for a single item because that’s how we anticipated our users interacting with it, but there’s not much stopping us from building it out to handle multiple requests later on if necessary. Additionally, the current design requires us to include ArchivesSpace refids in the our discovery system’s (DIMES) URL. Our DIMES URLs look like this: http://dimes.rockarch.org/xtf/view?docId=ead/FA392/FA392.xml;chunk.id=aspace_ref8_mfy;doc.view=contents;#aspace_ref9_jun ; anything following the # at the end is the AS refid. If you enter a URL into the FindIt search box, it just splits the string at the # and then searches for the refid as if you just entered the refid in by itself. If an instance does not contain any location information, FindIt will just tell you “No location found” and will not provide you an option to copy anything. We’ve also assumed that ArchivesSpace refids should be unique across the entire repository. Currently, if you have duplicate refids, which is technically possible but unlikely if you’ve let AS generate all of your refids, FindIt will only return the first result it finds, but we are working on a fix to this to return all valid refids in a search. We originally skewed towards simplicity with the results, but we definitely understand that duplicate refids could happen in the future.
Despite these caveats, we are moving forwards into a period of transition where we will have both FindIt and our master shelf list until we get all of our locations into ArchivesSpace. In the short-term, we’ll still have to find locations for some collections in Excel, but we’re excited about the future of flexible data in ArchivesSpace.