The following is the text from the talk I gave at METRO’s Annual Conference held this year on January 11, 2017. This talk was part of the panel “Getting More Out of (and Into) Your Collections Management System.”
I’m going to talk a bit about the RAC’s Digital Media Log. This is a place where archivists can identify digital media items during archival processing in order to plan for and perform preservation actions. This application is also where archivists can log basic digital media stabilization information.
Before providing the how’s and why’s of the Digital Media Log, I want to give a brief background on digital processing at the Rockefeller Archive Center. By “digital processing” I mean the description, arrangement, and initial preservation of born digital archival content stored on removable storage media. In our specific case, I’m mostly talking about floppy disks and CDs and DVDs. The workflows and processes that I’m going to focus on are related to establishing intellectual control of and stabilizing digital media, which generally means inventorying and disk imaging.
My unit, the Digital Programs Team, initially performed these activities but over the past year I’ve helped move these activities to the Processing Team. After all, our Processing Team’s mission is to establish and enhance intellectual and physical control of our archival holdings, regardless of their format. In addition, preserving and providing access to unique born digital content stored on obsolete and decaying media is time-sensitive, and we need all hands on deck. To achieve these, I’ve worked to provide processing archivists with the workflows and the tools needed to process digital materials.
One of the primary parts of this project was replacing our existing Digital Media Inventory and Tracking Database. This system had been used to provide detailed inventory and preservation tracking information for our digital media items, but the system had a number of drawbacks. It was clunky to use and multiple users could not use it at a time. Both of these factors were hindrances to encouraging archivists in other departments to work with born digital materials.
Additionally, the system required the user to manually enter information that was duplicated in other systems, including our collections management system-and often initially created by machines, such as the logs created through our disk imaging software. This meant that archivists’ time was spent copying and pasting instead of actually disk imaging our rapidly decaying and fragile media. Additionally, it meant that data was siloed and duplicated from our collections management system, which could create inconsistencies and confusion as well as being inefficient.
In thinking critically about our processes and needs, I realized that our ideal inventorying and tracking system:
- Would identify digital media items during processing in order to plan for and perform preservation actions
- Would log basic digital media preservation information
- Would enhance our data quality by providing a simplified data entry interface that used controlled vocabularies
- Would increase the efficiency of our inventorying process by making the system easier to use
- And would integrate with ArchivesSpace to reduce duplicate data entry, inconsistent data, and further integrate digital processing into our “regular” processing work.
After gathering requirements, I reached out to archivists at other institutions to see what systems they were using to inventory and track digital media items; I also looked at some systems for audiovisual materials. One system that I particularly liked, and from which I ultimately copied many features, was NYU’s Media Log. However, that and all other systems I looked at did not mean all of my requirements, mainly the integration with ArchivesSpace. I also explored recording this information in ArchivesSpace itself, but I did not want to mix information needed for internal administrative use with the description in our finding aids, and we did not want to make changes to the ArchivesSpace data model. Further, my ideal system would not be a canonical source of data about our disk imaging, but a place to record workflow steps that could spit out preservation metadata to be stored in another, more appropriate and permanent system.
So, we decided that building a system from scratch was the best way forward. But in order to do so, I needed to figure out what language to build it in. Before this project, I had experience with scripting in Python as well as some HTML, but had never built a web application before. I decided to use the Ruby on Rails framework because it is widely used and there is a lot of available documentation, and because the syntax is similar enough to Python, which I was already familiar with. These factors meant that I would be able to easily find resources and support as I learned Ruby on Rails and built my app, and that this could be used by institutions that are smaller or have fewer resources than the RAC, or do not have a dedicated developer.
There are plenty of Ruby and Rails tutorials resources out there, but for me I found Codecademy and Lynda.com to be the most useful. I also reverse-engineered the NYU Media Log-which I mentioned earlier-whose code is up on GitHub. And I had a lot of other support from great colleagues-my boss helped me through my struggles with JavaScript and Bootstrap, and I want to especially thank Dave Mayo at Harvard, who walked me through several issues that I had building a rails app and reviewed my code.
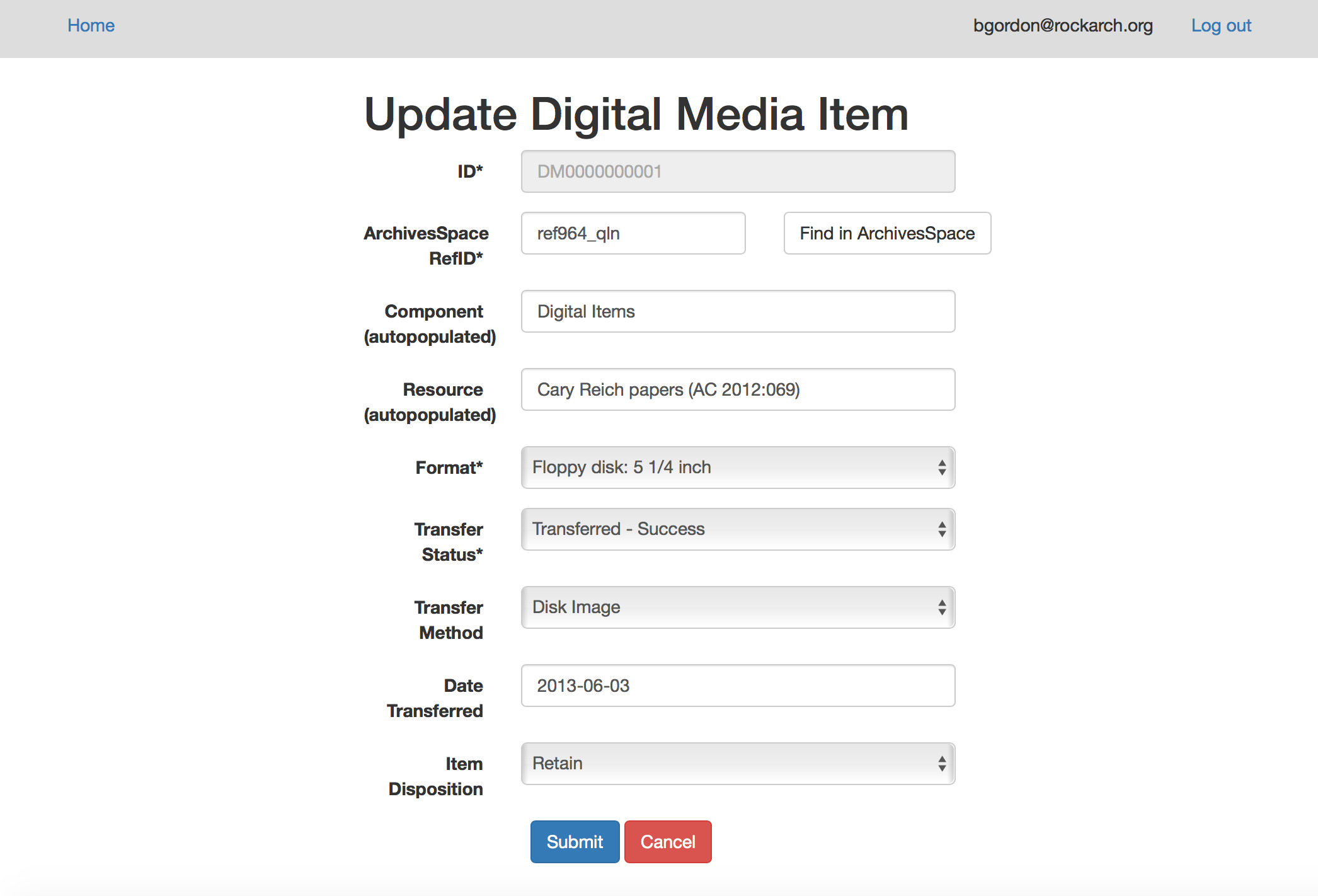
After many weeks of learning (and struggling with) Ruby, Rails, and JavaScript, I had a new Digital Media Log! Only 5 out of these ten fields need to be manually entered by a user, which means the actual data entry is minimal. The ID is auto generated, and the date transferred is auto populated with today’s date once the transfer method field changes. And you can’t see it here, but the Component and Resource title are populated after a user fills out the “ArchivesSpace RefID” field and clicks “Find in ArchivesSpace.” This is much faster and more efficient than copying and pasting or rekeying all that information. Now inventorying will not get in the way of actually preserving our born digital content. Additionally, making this process easier helps to encourage our processing archivists to work with born digital materials.
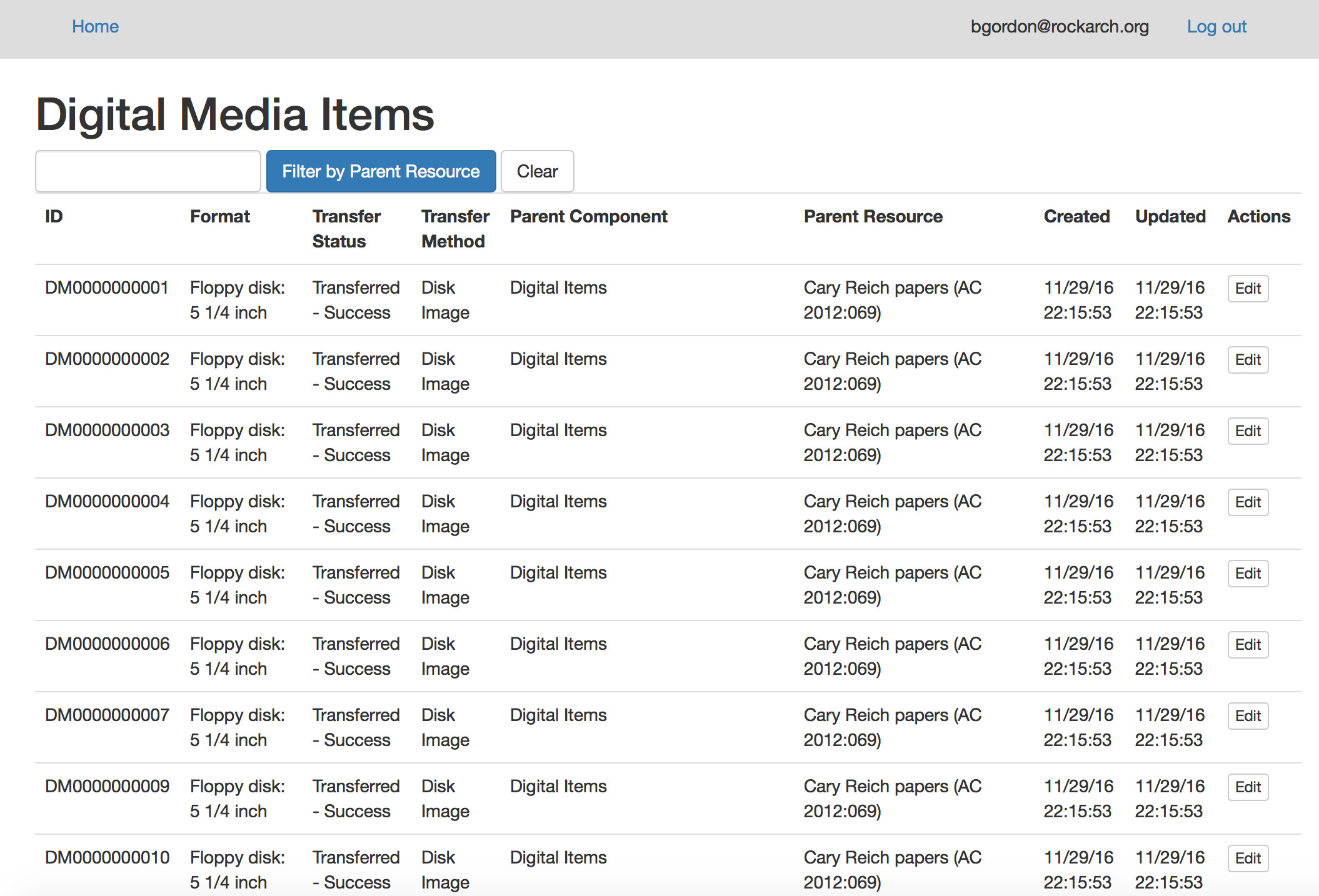
One step that I glossed over was migrating the data from the old system to the new system-which Amy did an immense amount of data cleanup for. While that step was a fair amount of work, I’m looking forward to how efficient this new system will be.
We’ve come a long way and the system is ready to be used in production. Despite this, there are still some limitations of the software and there are some features that I’d like to add; much of this stems from my prior inexperience building an application like this. For example, in order to use the ArchivesSpace API, a plugin needs to be installed in ArchivesSpace, which can be a limitation for adoption at other institutions. And there are some features, like being able to clone a record, that I’d like to add to make our processes even more efficient. But even with these limitations, being able to automate processes and harness the power of ArchivesSpace’s API in an outside system is a major step forward for us.