Several months ago, I wrote about our plans for the next phase of Project Electron, which targets infrastructure for the discovery and delivery of archival records. Since then, we’ve refined this high-level process proposal into working code. This post summarizes our work to date, and outlines current and ongoing efforts to improve system performance, integrate additional data sources, and improve the quality of our archival data.
Core Components
At its core, the data pipeline we’ve built consists of four services, which live in two different Django projects:
- Fetchers, which fetch updated and deleted data from data sources on a regular basis.
- Mergers, which merge data from different sources into a unified set of source objects.
- Transformers, which transform source objects into objects which comply with the RAC data model.
- Indexers, which add, update and delete data in our Elasticsearch index.
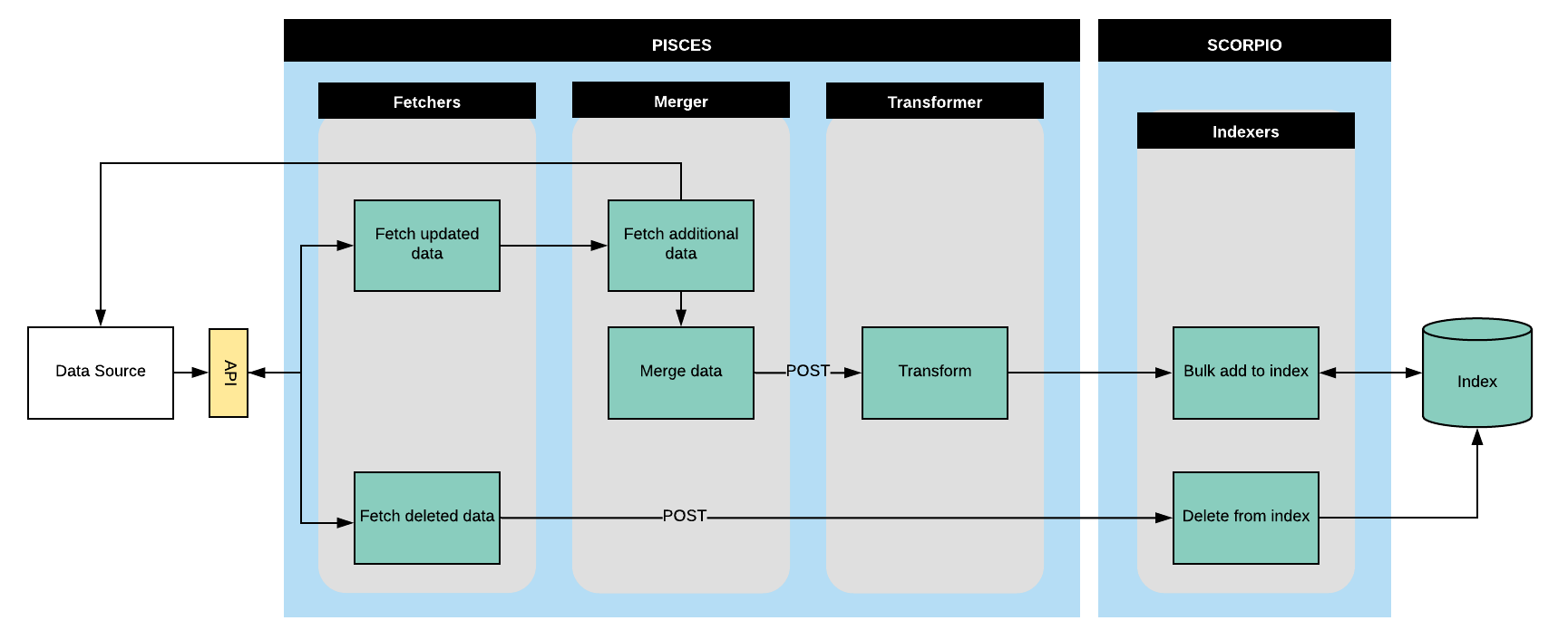
Let me explain how this will work with a hypothetical scenario. Let’s say a processing archivist finishes and publishes a finding aid they are working on in ArchivesSpace. Hooray! Now let’s get that data available to researchers as soon as possible.
On a regular basis, a Fetcher job runs against the ArchivesSpace API which asks for all of the recently updated resource records. The newly-completed finding aid is picked up by that request, and the Fetcher grabs all of the ArchivesSpace data about that resource and passes it along to the Merger.
The Merger takes the resource record data delivered to it and figures out what else it needs to fetch. In this case it might need to go back to ArchivesSpace to ask it for some more data about its immediate children, since the ArchivesSpace API makes resource trees available at a separate endpoint. When it gets all the data it needs, it sticks everything together and passes it off to the Transformer.
The Transformer takes the source data it gets from the Merger and transforms it to the appropriate RAC data model object, in this case a Collection. It then saves that transformed object in a database.
Last, on a regular basis, an Indexer job looks for any objects that haven’t been indexed, and indexes them in Elasticsearch. At this point the new finding aid is fully discoverable and searchable by researchers! Ideally this process happens in a matter of minutes; less time than it took you to read about it happening.
Next Steps
Although we have a working data pipeline, there is a lot more that needs to be done!
- We want to improve the performance of this pipeline to ensure that data flows through it as quickly as possible. We’ll be digging into the code more deeply to figure out where the less performant pieces are, and replace inefficient functions.
- So far our focus has been on moving data from ArchivesSpace into Elasticsearch. We’ll soon be looking to integrate additional data sources, including things like Wikidata and Wikipedia but also some more homegrown things like Cartographer (more on that soon!).
Last, as we’ve been working on this pipeline from the systems side of things, our Processing Team has been engaged in a number of projects to clean up our archival data. This is absolutely critical because, as Patrick wrote in an earlier post, we plan to make use of JSON Schemas to ensure data is valid before we index it. The Processing Team’s efforts are essential to this purpose, and also ensure that our data can support all the kinds of functionality we want to provide to researchers in our discovery and delivery interface. Stay tuned for more on that work, coming to this blog soon!