We’ve described in earlier posts changes we made to onsite digitization processes – including implementing ideas from the Toyota Production system and establishing file naming conventions – as a result of the service design research that Hannah conducted. However, it was also clear from the research that another major pain point in our digitization processes was handling the products of outsourced digitization processes.
Typically, when we send out a group of materials to be digitized by a vendor, we’d get the digitized files back from the vendor at the end of the project on an external hard drive. We’d load these files onto our local storage, do some manual renaming and restructuring of files, and then push them through a semi-automated pipeline which assigns structured rights statements, submits files for ingest, and finally makes access versions available online via DIMES. Not only does this process require a lot of manual intervention, it’s also incredibly tedious and error prone, puts a lot of strain on our local storage, and ultimately means there’s a long delay between the time when materials are digitized and when they are made available online.
Fortunately, we had an idea about how to improve this process, through the introduction of additional automation and scalable architecture.
Understanding the Process
Our outsourced digitization process has some specific characteristics:
- The files that it produces are predictable, homogenous, and can be at least partially validated using automated tools.
- The process tends to have a lot of peaks and valleys, so the infrastructure supporting it needs to be able to scale up quickly, but also to shut down completely when nothing needs to be processed.
- Perhaps most important, the outsourced digitization process is not just about creating files, but also includes post-digitization processes and systems to ensure access and preservation of those files. This might seem like an obvious thing, but it wasn’t to us prior to the service design research. In a way, the pain points outlined above existed because we hadn’t thought about these other pieces holistically.
These characteristics make our outsourced digitization processes a good candidate for automation.
Defining the Solution
Although we knew there were opportunities for automation, we also knew that there were barriers. The most significant of these was the range of file naming conventions and structures present in legacy digitized material. So the first thing we did was to develop and document a single structure and file naming convention for all of our digitized content. Hannah wrote in an earlier blog post about how this supports automation in our onsite digitization processes, and the same is true for our outsourced processes. In addition, by removing the need to manually rename files and directories, we removed dependence on our local storage and opened up the possibility for delivering and processing these digitized materials entirely in the cloud without having to load them on several different types of storage.
The pipeline we built to handle digitized content from vendors is very similar to the one that we built for handling digitized audiovisual materials: it uses cloud services to automate validation and packaging of digitized content, with a web interface that supports quality control by a human.
From a technical perspective, this pipeline makes extensive use of Amazon Web Services (AWS) services. Two Elastic Container Service (ECS) tasks and one service encapsulate most of the main business logic, with a Simple Notification Service (SNS) message queue to tie them together, along with some Lambda scripts to send notifications to a Teams channel and trigger ECS tasks. Digitized files are stored in S3 buckets.
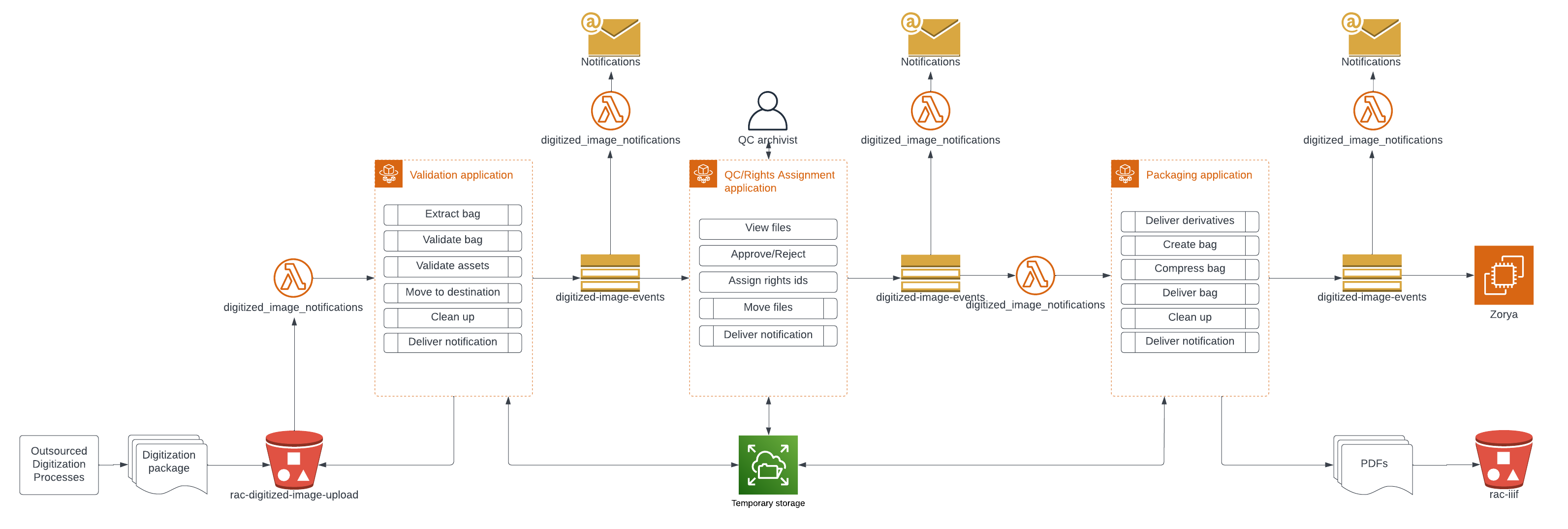
The source code for each piece of this pipeline is versioned in its own repository (which allows each component to be updated independently) and the infrastructure-as-code templates which provision cloud resources are stored in their own repository:
- digitized_image_validation: validates the fixity, structure and file characteristics of incoming digitized material.
- digitized_image_qc: provides a web user interface for quality control and rights assignment.
- digitized_image_packaging: creates packages of accepted digitized material and delivers it to subsequent services.
- digitized_image_notifications: handles SNS messages and sends messages to a Teams channel about failures or other significant events.
- digitized_image_trigger: triggers ECS tasks when files are uploaded to an S3 bucket, or when an SNS message indicates that quality control has been successfully completed.
- digitized_image_pipeline: contains CloudFormation templates for provisioning infrastructure.
Connecting to Values
While the technology part of this project is interesting, to me the most compelling part is the strong connection this work has to the RAC’s organizational values.
- The project supports our first value, “We Pursue Excellence in Stewardship” in a number of ways. First, by automating work that was previously manual, we are better stewards of our own labor. Additionally, by not running idle processes, and by being able to more clearly define how many copies we store (and where we store them) we are able to reduce our environmental impact. Last, by facilitating ongoing software updates and limiting the depth and complexity of hardware we need to maintain locally (particularly storage and backups), we provide better stewardship of technical expertise and equipment.
- By removing manual processes, we also meet another organizational value, “We Center People in Our Use of Technology”. Taking tedious, error prone work off the plate of our colleagues allows them to apply their labor in more humanizing ways.