We are excited to announce the launch of our new archival discovery system at the Rockefeller Archive Center. This next generation of DIMES - which we’ve been calling DIMES-TNG - is a major overhaul of both our public-facing website for searching archival collections and accessing digitized content, as well as its underlying infrastructure. The launch of this site marks the final major milestone for Project Electron, an RAC effort to build sustainable, user-centered, and standards-compliant infrastructure to support the ongoing acquisition, management, and preservation of archival digital records in order to make archival records available in the broadest and most equitable way possible. As the piece that focuses specifically on access, DIMES-TNG is the culmination of Project Electron.
Why a new DIMES?
Many things have changed since the Rockefeller Archive Center released its first version of DIMES (based on the XTF framework) back in 2012. DIMES-TNG leverages and builds on changes at the RAC, in technology, and in the world of archival theory and practice.
First, the RAC has made major strides in standardizing and speeding up archival processing to eliminate our backlog and release smaller aggregations of materials more quickly. This has typically meant that records from a single creator are represented by many small resource records in ArchivesSpace rather than a single large one. The new DIMES allows us to meaningfully tie these resources together in “arrangement maps”. We’ve also built up competency using APIs, which has enabled some significant ArchivesSpace data cleanup projects and better integrations for faster updates and interoperability between systems.
Additionally, we’ve developed a usability testing program and leveraged UX methodologies to truly center users in our design processes, along with defining our guiding principles for archival access. Relatedly, we’ve significantly leveled-up our competencies related to web accessibility standards to be able to bake in WCAG 2.1 AA recommendations as requirements from the beginning in order to support a range of assistive technologies and device sizes.
Finally, the new DACS principles point to the importance of describing records, agents, activities, and the relationships between them. Our old system didn’t provide meaningful browsing and navigation of these entities or relationships.
How did we build DIMES?
The development of DIMES-TNG began with and was shaped by people, not any specific technology. Project Electron has always been about the collaborative development of processes, roles, and expertise. Our staff users from all RAC Program areas (Reference, Processing, Collections Development, Research and Education, and Digital Strategies) have been involved in the design process, contributing their expertise from the earliest stages of the work by gathering user stories, creating personas, collaborative data modeling, reviewing wireframes, and participating in, conducting, and observing usability tests. In striving to center people, value their labor and expertise, rely on their skills and knowledge, and develop new competencies together, we built DIMES-TNG in a way that we hope is maintainable, enhances discovery and access, and continues to allow us to grow as an organization.
Data and system architecture
DIMES-TNG is not just one system. In addition to a user-facing website built using React, it also includes underlying infrastructure to move, transform, and index data, an image pipeline, a IIIF image server, and a Request Broker application to facilitate the parsing and delivery of requests from the frontend to our retrieval management system (Aeon).
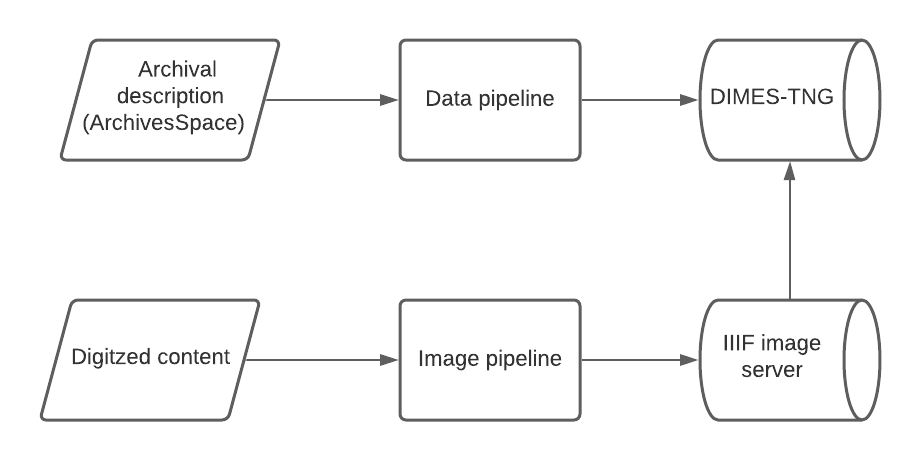
How does data get to DIMES?
I won’t go into too much depth here, as each piece of the system’s architecture has or will soon have its own post for folks who want a deep dive. Basically, we have built a data pipeline to regularly fetch updated or deleted data from ArchivesSpace using its API, merge that data into a unified set of source objects, transform those objects to comply with our data model, and finally add and index the data using Elasticsearch to enable users to search the data in the DIMES-TNG website. This pipeline process is a major performance improvement for us, happening in minutes instead of the nightly data export we used to depend on.
Between the Elasticsearch index and DIMES-TNG, there is an API middleware application called Argo. Argo formats the data from the search index into a standardized structure upon requests from the discovery interface, which lets us decouple the index and interface and creates a stable way to display our archival data to machines.
How does digitized content get to DIMES?
From digitization to Archivematica to DIMES-TNG, we’ve made some major changes to streamline and automate our “image pipeline” processes. These include implementing and leveraging machine actionable rights statements that follow the PREMIS metadata standard, automating the creation of access files, and implementing a IIIF image server (International Image Interoperability Framework). For users of DIMES-TNG, this means being able to take advantage of IIIF technologies when accessing digital objects via the Mirador IIIF Viewer. Stay tuned for a more in-depth breakdown of the image pipeline in an upcoming post.
What’s Next?
We will continue to refine, improve, and enhance DIMES-TNG after it launches. Conducting multiple iterative rounds of usability testing of the frontend interface during the development process helped us identify areas for improvement. We have also received useful feedback from RAC staff users over the past 2 months after an internal site launch allowed staff to test and explore the new system, which allowed us to further refine the site’s functionality and features. We also plan to enhance our implementation of the digital object viewer to display audiovisual material and incorporate more advanced features.
As always, everything we build is open source and available on the Rockefeller Archive Center GitHub, and we welcome thoughts and questions!