We just deployed a major re-architecting of our digital ingest services which we believe will improve the energy efficiency, speed and maintainability of this pipeline. This project has been a while in the making, so I thought I’d take the time to reflect on where we’ve been, where we are now, and what comes next.
Where We Started
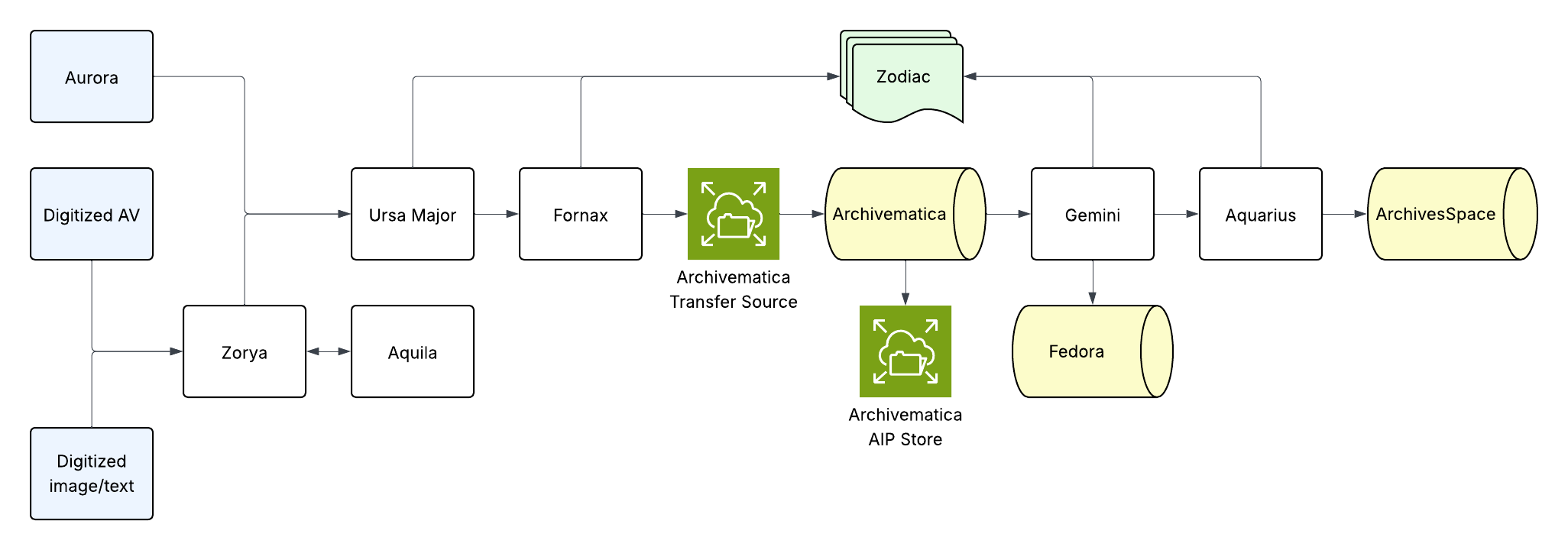
We built the original version of this pipeline back in 2019 as part of Project Electron, an initiative to build sustainable, user-centered and standards-compliant infrastructure to support the ongoing acquisition, management and preservation of digital records. As we conceived of it then, the pipeline integrated Aurora (our home-grown appraisal and accessioning application) with Archivematica and ArchivesSpace, automating the ingest of born-digital records from donor organizations. Over time, we started to use this same pipeline for digitized content as well, adding additional services and intake pipelines for digitized audiovisual and image and text materials.
At its most complex, this pipeline was architected as six Django web apps, each with a handful of services that could be called via HTTP. The results of individual events in each were logged to a central user interface, which we called Zodiac.
Encountering Challenges
This pipeline made it possible for us to start acquiring born-digital records, which was a huge leap forward for the organization. However, as we worked with this pipeline over time, some drawbacks became apparent:
- Because they were triggered by HTTP, long-running services would often time out, resulting in us adding additional services to make them more atomic and introducing process statuses. Still, some services continued to time out consistently, resulting in misleading error messages in the Zodiac user interface.
- We also discovered that the usage pattern for this pipeline was very uneven, resulting in spikes of activity separated by often lengthy periods of no activity. This meant that there were often many months out of the year when the servers these services were running on were running idle, and a few months where their resources were maxed out.
- In addition, because all the applications were deployed on a server, they were subject to the resource limitations of that server. If the server ran out of processing power, memory, or disk space, everything stopped. In an effort to even out these spikes and valleys, we throttled throughput, which meant that it took a lot longer for packages to process through the pipeline. Additionally, if one package encountered an error, it would back up everything behind it, further increasing processing time.
- Finally, ongoing maintenance was challenging to complete while transfers were in process because automated deployments would often result in transfers being “stuck”. Resolving this required careful manual intervention, which undermined the efficiencies gained through continuous integration and deployment.
Where We Are Now
As a result, we’d been thinking about ways to improve this pipeline for some time, and it became clear that, while the internal logic of many of the services was solid, solving the problems we were experiencing would require us to reimplement existing logic in a different systems architecture. When we originally built these pipelines, cloud-based services were not part of our thinking. In the years since, as we have increasingly moved systems and storage to AWS, we’ve more fully understood the potential of managed services.
In particular, the ability to use “serverless” services seemed like a good match for solving the problems we were encountering. These services allow compute and storage resources to be allocated and used on an as-needed basis, meaning that we could run our code without having to purchase and maintain servers (hence the “serverless” – it’s not that there aren’t servers involved, it’s just that they aren’t your problem). The AWS service we ended up using – Elastic Container Service (or ECS) – allows us to run Docker images as containers. We packaged up the services as ECS Tasks and used AWS’s Simple Notifications Service plus some Lambdas to trigger these Tasks as needed.
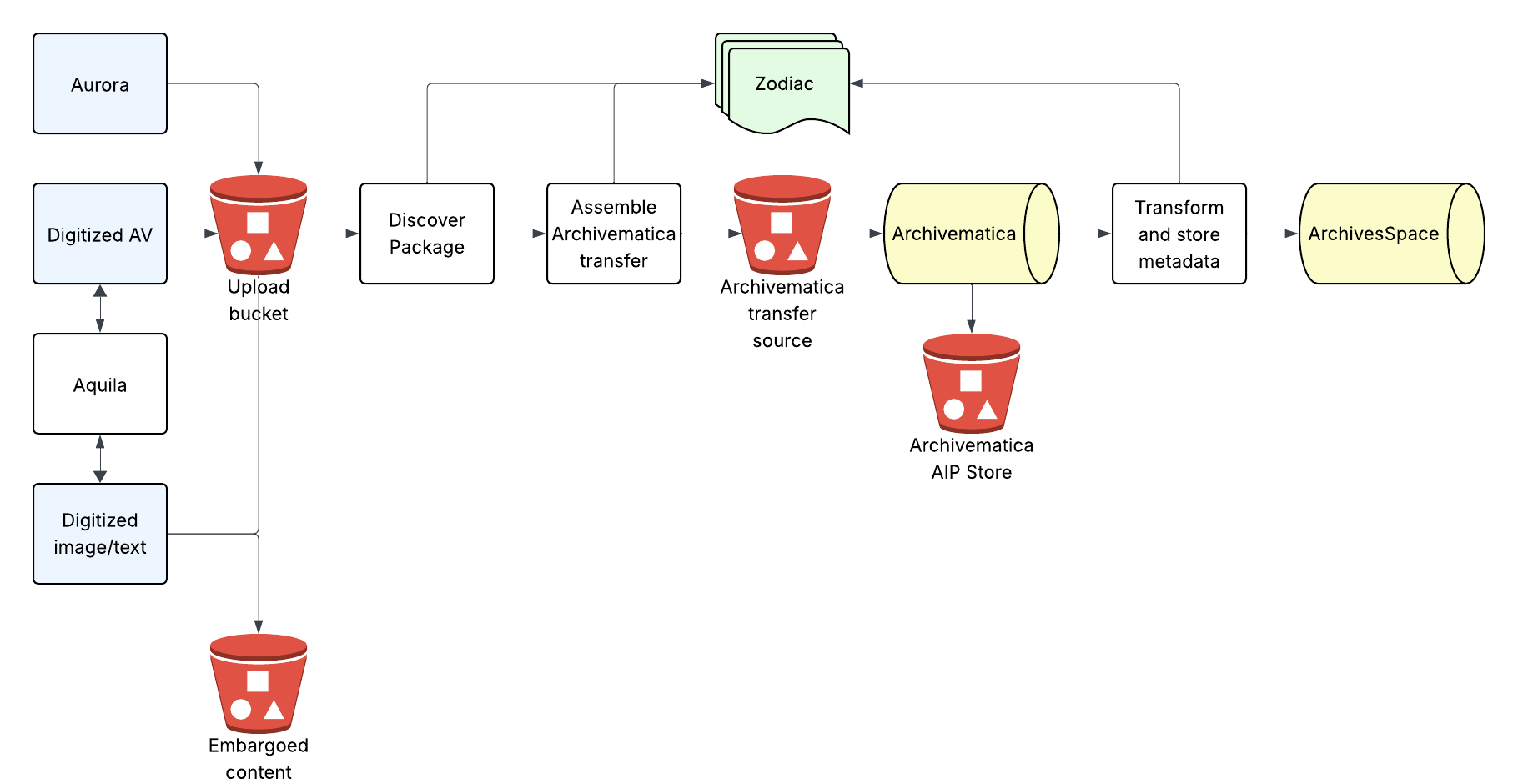
This new architecture solves many of the challenges we were experiencing:
- Because each instance of a Task is resourced separately, if one service is more resource-intensive than another we can add the necessary resources in a very targeted way.
- We can also run more than one instance of a Task at a time, so the pipeline better supports the spiky usage pattern we’ve been observing, and overall throughput is much faster.
- Failures are isolated and don’t block processing of other packages.
- Deployments are seamless and quick, and don’t impact packages in process. This project also gave us the opportunity to dig into Infrastructure-as-Code (IAC) practices. That’s probably another blog post by itself but using IAC has been a key part of mitigating the complexity that comes with managing resources and permissions in serverless services.
- Because we’re only consuming the resources we need, the energy usage we’re directly responsible for is decreased significantly. As noted above, there’s still a server somewhere that’s running, so while it is theoretically possible that using this technology may increase the overall efficiency of the data center in which the code is running it is far from certain (and difficult to prove or disprove).
We also took the opportunity to redesign the user interface for this pipeline, separating it into a backend API as well as a React/NextJS frontend which we developed through a collaborative process of developing wireframes and user stories with users of the previous interface. One of the key changes we made was to center the UI around packages, rather than individual events which – as our user testing confirmed – shows the progress of a package through the pipeline much more clearly.
What’s Next
We’ll be migrating some additional pipelines that support our IIIF implementation and fetch and transform data for use in DIMES to this same architecture. This will give us an opportunity to review how activity in those pipelines is logged and presented to users. As we do this we’ll also be measuring how this new architecture impacts our AWS costs, and likely looking for ways to optimize cost.